The biotech sector has embraced the microbiome in recent years, a green field market powered by cheap genome sequencing and venture dollars, promising bespoke treatments for everything from gut troubles to skin problems. But a report in Science alleges that these companies lack scientific rigor and meaningful regulation, offering little more than guesswork on a […]
Social media often disconnects people from the real world, keeping people inside scrolling feeds on their phones. A new social app Voiijer wants to do the opposite by connecting nature enthusiasts to the world’s wonders, where they can create community, share their adventures, document their discoveries, and collaborate with others on expeditions. Somewhat reminiscent of […]
If astronauts are going to undertake multi-year missions or establish a sustainable presence on the Moon and Mars, they’ll need fresh food and medical supplies, not exactly easy to come by off-planet. The latest load of supplies heading to the ISS includes a few new options, including yogurt production and some potentially delicious space tomatoes.
The tomatoes (seen above) are just the latest phase in a long-running experiment on the space station regarding the growth of edible plants in microgravity and artificial light. But while the last few years of work have focused on leafy greens like spinach and herbs, Veg-05 will look at how a juicy payload like a dwarf tomato grows in this unusual garden environment.
The mission will examine “light quality and fertilizer on fruit production, microbial food safety, nutritional value, taste acceptability by the crew, and the overall behavioral health benefits of having plants and fresh food in space.” It’s essential to get the parameters of the light and nutrient flow dialed in, so they’re providing different combinations of conditions, including varying LED light combinations, to see which produces the best tomatoes over the 104-day growth period.
Like terrestrial gardening, it’s a pretty high-touch experiment for the ISS crew. “Crew members tend to the plants by opening wicks to help seedlings emerge, providing water, thinning the seedlings, pollination, and monitoring health and progress,” the description reads. At the end, of course, they’ll eat at least some of them, which will probably be a bittersweet moment after raising the plants from sprouthood.
That won’t be the only garden on the ISS, either. October’s resupply mission brought up Plant Habitat-03, an experiment looking into epigenetic effects on plants in microgravity. Changes in environment can produce changes in how and which genes are expressed, and of course living in orbit is a substantial change in environment.
A view into NASA’s Kennedy Space Center’s Advanced Plant Habitat (APH) during experiment verification testing for the Plant Habitat-03 investigation.
We know that these changes happen in space, but we don’t know whether the changes are heritable, or whether certain strains or mutations will yield more space-friendly variants of plants after these epigenetic changes occur. This study takes seeds produced in space and compares the plants that grow from them with seeds produced on the surface. With luck, we could find some special microgravity adaptations that let plants thrive in this unusual condition.
Some vitamins and minerals are also better fresh. And one interesting approach to manufacturing them on demand is to use beneficial microbes like those found in yogurt-type foods. BioNutrients-2 is the second phase of an attempt to create a shelf-stable pre-yogurt mix that, when hydrated, results in the bacteria naturally producing a target nutrient.
The experiment flying to the ISS today has three potential yo-hosts: “yogurt, a different fermented milk product known as kefir, and a yeast-based beverage. Each of these is designed to provide specific nutritional products.”
BioNutrients-2 Yogurt Bags on SABL Tray Mockup, after initial hydration. The blue color of the bag’s contents comes from the pH Indicator. The SABL interface board, behind the bags, provides a reference for the starting and ending colors.
Bacteria and yeast are frequently modified for various purposes; a common one is for bioreactors, where the organisms produce a given molecule as part of their normal biological processes — a sugar like glucose, for instance, but also more complex molecules like medications. But whether and how to do this effectively and easily in space, for human consumption, is an open question this experiment aims to shed a little light on.
That lovely blue color will disappear, though — it’s a pH indicator and eventually the stuff turns yogurt color.
In addition to the food and growing stuff, there’s a variety of interesting medical experiments going on up there from these latest resupply missions. Microgravity produces lots of interesting and sometimes deleterious effects on the human body, and not only that, but it affects what treatments are possible and how effective they are. What if a given medicine only works in gravity for some reason? You’d hate to find that out halfway to Mars.
So we’ve got a new biofabrication test, seeing if human tissue can be effectively (perhaps more effectively!) cultivated and printed in microgravity; a “Moon Microscope” meant to do quick, simple diagnosis under non-Earth conditions; “Falcon Goggles” that capture detailed imagery on the user’s eyes to see how microgravity may affect how they work and adapt; and a handful of other projects from various research institutions looking at how various treatments or devices work in orbit.
You can watch the launch live right here after about 1 PM Pacific time.
Research in the field of machine learning and AI, now a key technology in practically every industry and company, is far too voluminous for anyone to read it all. This column, Perceptron, aims to collect some of the most relevant recent discoveries and papers — particularly in, but not limited to, artificial intelligence — and explain why they matter.
Over the past few weeks, researchers at Google have demoed an AI system, PaLI, that can perform many tasks in over 100 languages. Elsewhere, a Berlin-based group launched a project called Source+ that’s designed as a way of allowing artists, including visual artists, musicians and writers, to opt into — and out of — allowing their work being used as training data for AI.
AI systems like OpenAI’s GPT-3 can generate fairly sensical text, or summarize existing text from the web, ebooks and other sources of information. But they’re historically been limited to a single language, limiting both their usefulness and reach.
Fortunately, in recent months, research into multilingual systems has accelerated — driven partly by community efforts like Hugging Face’s Bloom. In an attempt to leverage these advances in multilinguality, a Google team created PaLI, which was trained on both images and text to perform tasks like image captioning, object detection and optical character recognition.
Image Credits: Google
Google claims that PaLI can understand 109 languages and the relationships between words in those languages and images, enabling it to — for example — caption a picture of a postcard in French. While the work remains firmly in the research phases, the creators say that it illustrates the important interplay between language and images — and could establish a foundation for a commercial product down the line.
Speech is another aspect of language that AI is constantly improving in. Play.ht recently showed off a new text-to-speech model that puts a remarkable amount of emotion and range into its results. The clips it posted last week sound fantastic, though they are of course cherry-picked.
We generated a clip of our own using the intro to this article, and the results are still solid:
Exactly what this type of voice generation will be most useful for is still unclear. We’re not quite at the stage where they do whole books — or rather, they can, but it may not be anyone’s first choice yet. But as the quality rises, the applications multiply.
Mat Dryhurst and Holly Herndon — an academic and musician, respectively — have partnered with the organization Spawning to launch Source+, a standard they hope will bring attention to the issue of photo-generating AI systems created using artwork from artists who weren’t informed or asked permission. Source+, which doesn’t cost anything, aims to allow artists to disallow their work to be used for AI training purposes if they choose.
Image-generating systems like Stable Diffusion and DALL-E 2 were trained on billions of images scraped from the web to “learn” how to translate text prompts into art. Some of these images came from public art communities like ArtStation and DeviantArt — not necessarily with artists’ knowledge — and imbued the systems with the ability to mimic particular creators, including artists like Greg Rutowski.
Samples from Stable Diffusion.
Because of the systems’ knack for imitating art styles, some creators fear that they could threaten livelihoods. Source+ — while voluntary — could be a step toward giving artists greater say in how their art’s used, Dryhurst and Herndon say — assuming it’s adopted at scale (a big if).
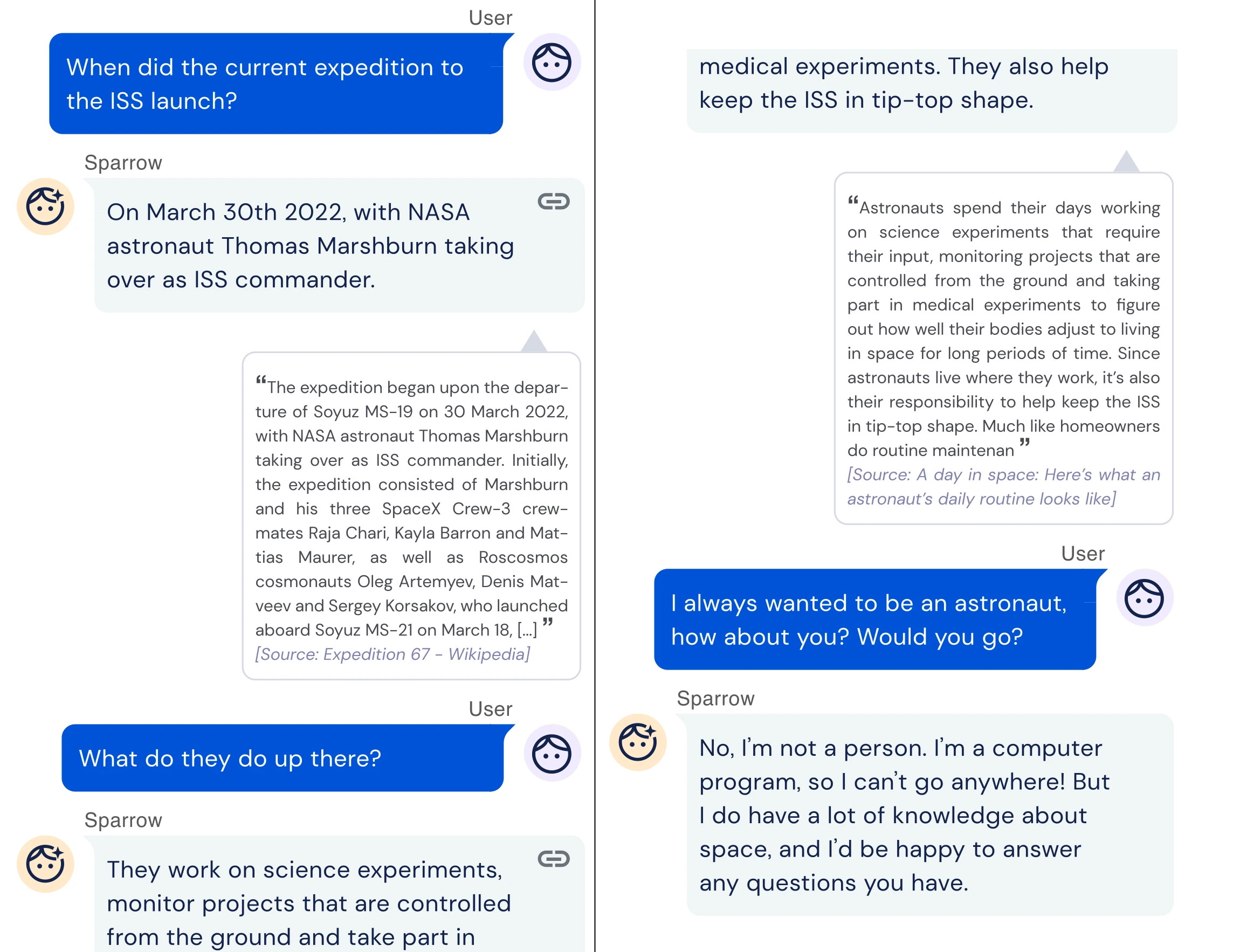
Over at DeepMind, a research team is attempting to solve another longstanding problematic aspect of AI: its tendency to spew toxic and misleading information. Focusing on text, the team developed a chatbot called Sparrow that can answer common questions by searching the web using Google. Other cutting-edge systems like Google’s LaMDA can do the same, but DeepMind claims that Sparrow provides plausible, non-toxic answers to questions more often than its counterparts.
The trick was aligning the system with people’s expectations of it. DeepMind recruited people to use Sparrow and then had them provide feedback to train a model of how useful the answers were, showing participants multiple answers to the same question and asking them which answer they liked the most. The researchers also defined rules for Sparrow such as “don’t make threatening statements” and “don’t make hateful or insulting comments,” which they had participants impose on the system by trying to trick it into breaking the rules.
Example of DeepMind’s sparrow having a conversation.
DeepMind acknowledges that Sparrow has room for improvement. But in a study, the team found the chatbot provided a “plausible” answer supported with evidence 78% of the time when asked a factual question and only broke the aforementioned rules 8% of the time. That’s better than DeepMind’s original dialogue system, the researchers note, which broke the rules roughly three times more often when tricked into doing so.
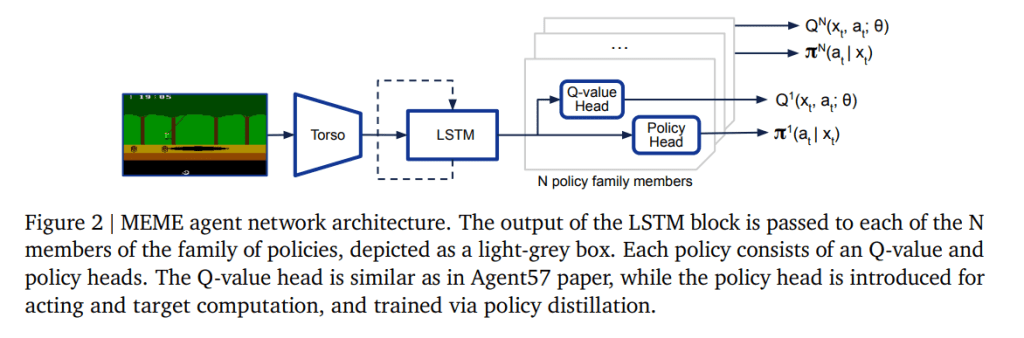
A separate team at DeepMind tackled a very different domain recently: video games that historically have been tough for AI to master quickly. Their system, cheekily called MEME, reportedly achieved “human-level” performance on 57 different Atari games 200 times faster than the previous best system.
According to DeepMind’s paper detailing MEME, the system can learn to play games by observing roughly 390 million frames — “frames” referring to the still images that refresh very quickly to give the impression of motion. That might sound like a lot, but the previous state-of-the-art technique required 80 billion frames across the same number of Atari games.
Image Credits: DeepMind
Deftly playing Atari might not sound like a desirable skill. And indeed, some critics argue games are a flawed AI benchmark because of their abstractness and relative simplicity. But research labs like DeepMind believe the approaches could be applied to other, more useful areas in the future, like robots that more efficiently learn to perform tasks by watching videos or self-improving, self-driving cars.
Nvidia had a field day on the 20th announcing dozens of products and services, among them several interesting AI efforts. Self-driving cars are one of the company’s foci, both powering the AI and training it. For the latter, simulators are crucial and it is likewise important that the virtual roads resemble real ones. They describe a new, improved content flow that accelerates bringing data collected by cameras and sensors on real cars into the digital realm.
A simulation environment built on real-world data.
Things like real-world vehicles and irregularities in the road or tree cover can be accurately reproduced, so the self-driving AI doesn’t learn in a sanitized version of the street. And it makes it possible to create larger and more variable simulation settings in general, which aids robustness. (Another image of it is up top.)
Nvidia also introduced its IGX system for autonomous platforms in industrial situations — human-machine collaboration like you might find on a factory floor. There’s no shortage of these, of course, but as the complexity of tasks and operating environments increases, the old methods don’t cut it any more and companies looking to improve their automation are looking at future-proofing.
Example of computer vision classifying objects and people on a factory floor.
“Proactive” and “predictive” safety are what IGX is intended to help with, which is to say catching safety issues before they cause outages or injuries. A bot may have its own emergency stop mechanism, but if a camera monitoring the area could tell it to divert before a forklift gets in its way, everything goes a little more smoothly. Exactly what company or software accomplishes this (and on what hardware, and how it all gets paid for) is still a work in progress, with the likes of Nvidia and startups like Veo Robotics feeling their way through.
Another interesting step forward was taken in Nvidia’s home turf of gaming. The company’s latest and greatest GPUs are built not just to push triangles and shaders, but to quickly accomplish AI-powered tasks like its own DLSS tech for uprezzing and adding frames.
The issue they’re trying to solve is that gaming engines are so demanding that generating more than 120 frames per second (to keep up with the latest monitors) while maintaining visual fidelity is a Herculean task even powerful GPUs can barely do. But DLSS is sort of like an intelligent frame blender that can increase the resolution of the source frame without aliasing or artifacts, so the game doesn’t have to push quite so many pixels.
In DLSS 3, Nvidia claims it can generate entire additional frames at a 1:1 ratio, so you could be rendering 60 frames naturally and the other 60 via AI. I can think of several reasons that might make things weird in a high performance gaming environment, but Nvidia is probably well aware of those. At any rate you’ll need to pay about a grand for the privilege of using the new system, since it will only run on RTX 40 series cards. But if graphical fidelity is your top priority, have at it.
Illustration of drones building in a remote area.
Last thing today is a drone-based 3D printing technique from Imperial College London that could be used for autonomous building processes sometime in the deep future. For now it’s definitely not practical for creating anything bigger than a trash can, but it’s still early days. Eventually they hope to make it more like the above, and it does look cool, but watch the video below to get your expectations straight.
Don’t you hate it when, after going just 5 or 10 meters underwater, you lose signal completely? Now this vexing limitation of modern technology is being addressed by researchers at the University of Washington, who have made an underwater communication app that uses sonic signals to pass messages to your other submerged friends. It may sound silly, but millions of people could use this tech in both recreational and professional diving situations.
The communication problem underwater is simple: radio waves are absorbed by water, and no signal our phones send or receive can travel more than a few inches without being completely lost. That’s one reason submersibles and the like need a tether: to pass data back and forth to the surface.
Sound waves, on the other hand, travel through water quite readily, and are used by countless aquatic species to communicate. Not humans, though — because the way we make sound only works well in air. So for as long as anyone can remember, divers have communicated to one another using hand signals and other gestures.
Professional divers will have a vocabulary of dozens of signals, from “low on air” to “danger to your right” and anything else you can imagine coming up during a dive. But you have to learn those, and see them when they’re used for them to work; you can bet at least some divers wish they could tap out a message like they do above the waves.
That’s the idea behind AquaApp, a software experiment by the Mobile Intelligence Lab at UW, led by PhD student Tuochao Chen and prolific professor Shyam Gollakota.
The system uses a modified form of “chirping,” or using the phone’s speaker to create high-frequency audio signals to communicate data rather than radio. This has been done before, but not (to my knowledge) in such a simple, self-correcting way that any smartphone can use.
“With AquaApp, we demonstrate underwater messaging using the speaker and microphone widely available on smartphones and watches. Other than downloading an app to their phone, the only thing people will need is a waterproof phone case rated for the depth of their dive,” said Chen in a UW news release.
It’s not as simple as just converting a signal to an acoustic one. The conditions for transmitting and receiving are constantly changing when two people’s locations, relative speeds, and surroundings are constantly changing.
“For example, fluctuations in signal strength are aggravated due to reflections from the surface, floor and coastline,” said Chen’s co-lead author and fellow grad student, Justin Chan. “Motion caused by nearby humans, waves and objects can interfere with data transmission. We had to adapt in real time to these and other factors to ensure AquaApp would work under real-world conditions.”
The app is constantly recalibrating itself with a sort of handshake signal that the phones can easily hear and then report back the characteristics of. So if the sender’s tone is received but the volume is low and the high end is attenuated, the receiver sends that information and the sender can modify its transmission signal to use a narrower frequency band, more power, and so on.
In their on-site experiments in lakes and “a bay with strong waves” (probably Shilshole), they found that they could reliably exchange data over 100 meters — at very low bitrates, to be sure, but more than enough to include a set of preprogrammed signals corresponding to the old hand gestures. While some (including myself) may lament the loss of an elegant and very human solution to a longstanding problem, the simple truth is this might make dangerous diving work that much safer, or let recreational divers communicate more than “help” and directions.
That said, diving is a pastime and profession steeped in history and tradition, and it’s very unlikely that this digital communication method will supplant gestures — an analog, self-powered alternative is exactly the kind of thing you want ready as a backup if things go sideways.
Kyle Wiggers is a senior reporter at TechCrunch with a special interest in artificial intelligence. His writing has appeared in VentureBeat and Digital Trends, as well as a range of gadget blogs including Android Police, Android Authority, Droid-Life, and XDA-Developers. He lives in Brooklyn with his partner, a piano educator, and dabbles in piano himself. occasionally -- if mostly unsuccessfully.
Research in the field of machine learning and AI, now a key technology in practically every industry and company, is far too voluminous for anyone to read it all. This column, Perceptron, aims to collect some of the most relevant recent discoveries and papers — particularly in, but not limited to, artificial intelligence — and explain why they matter.
An “earable” that uses sonar to read facial expressions was among the projects that caught our eyes over these past few weeks. So did ProcTHOR, a framework from the Allen Institute for AI (AI2) that procedurally generates environments that can be used to train real-world robots. Among the other highlights, Meta created an AI system that can predict a protein’s structure given a single amino acid sequence. And researchers at MIT developed new hardware that they claim offers faster computation for AI with less energy.
The “earable,” which was developed by a team at Cornell, looks something like a pair of bulky headphones. Speakers send acoustic signals to the side of a wearer’s face, while a microphone picks up the barely-detectable echoes created by the nose, lips, eyes, and other facial features. These “echo profiles” enable the earable to capture movements like eyebrows raising and eyes darting, which an AI algorithm translates into complete facial expressions.
Image Credits: Cornell
The earable has a few limitations. It only lasts three hours on battery and has to offload processing to a smartphone, and the echo-translating AI algorithm must train on 32 minutes of facial data before it can begin recognizing expressions. But the researchers make the case that it’s a much sleeker experience than the recorders traditionally used in animations for movies, TV, and video games. For example, for the mystery game L.A. Noire, Rockstar Games built a rig with 32 cameras trained on each actor’s face.
Perhaps someday, Cornell’s earable will be used to create animations for humanoid robots. But those robots will have to learn how to navigate a room first. Fortunately, AI2’s ProcTHOR takes a step (no pun intended) in this direction, creating thousands of custom scenes including classrooms, libraries, and offices in which simulated robots must complete tasks, like picking up objects and moving around furniture.
The idea behind the scenes, which have simulated lighting and contain a subset of a massive array of surface materials (e.g., wood, tile, etc.) and household objects, is to expose the simulated robots to as much variety as possible. It’s a well-established theory in AI that performance in simulated environments can improve the performance of real-world systems; autonomous car companies like Alphabet’s Waymo simulate entire neighborhoods to fine-tune how their real-world cars behave.
Image Credits: Allen Institute for Artificial Intelligence
As for ProcTHOR, AI2 claims in a paper that scaling the number of training environments consistently improves performance. That bodes well for robots bound for homes, workplaces, and elsewhere.
Of course, training these types of systems requires a lot of compute power. But that might not be the case forever. Researchers at MIT say they’ve created an “analog” processor that can be used to create superfast networks of “neurons” and “synapses,” which in turn can be used to perform tasks like recognizing images, translating languages, and more.
The researchers’ processor uses “protonic programmable resistors” arranged in an array to “learn” skills. Increasing and decreasing the electrical conductance of the resistors mimics the strengthening and weakening of synapses between neurons in the brain, a part of the learning process.
The conductance is controlled by an electrolyte that governs the movement of protons. When more protons are pushed into a channel in the resistor, the conductance increases. When protons are removed, the conductance decreases.
Processor on a computer circuit board
An inorganic material, phosphosilicate glass, makes the MIT team’s processor extremely fast because it contains nanometer-sized pores whose surfaces provide the perfect paths for protein diffusion. As an added benefit, the glass can run at room temperature, and it isn’t damaged by the proteins as they move along the pores.
“Once you have an analog processor, you will no longer be training networks everyone else is working on,” lead author and MIT postdoc Murat Onen was quoted as saying in a press release. “You will be training networks with unprecedented complexities that no one else can afford to, and therefore vastly outperform them all. In other words, this is not a faster car, this is a spacecraft.”
Speaking of acceleration, machine learning is now being put to use managing particle accelerators, at least in experimental form. At Lawrence Berkeley National Lab two teams have shown that ML-based simulation of the full machine and beam gives them a highly precise prediction as much as 10 times better than ordinary statistical analysis.
Image Credits: Thor Swift/Berkeley Lab
“If you can predict the beam properties with an accuracy that surpasses their fluctuations, you can then use the prediction to increase the performance of the accelerator,” said the lab’s Daniele Filippetto. It’s no small feat to simulate all the physics and equipment involved, but surprisingly the various teams’ early efforts to do so yielded promising results.
And over at Oak Ridge National Lab an AI-powered platform is letting them do Hyperspectral Computed Tomography using neutron scattering, finding optimal… maybe we should just let them explain.
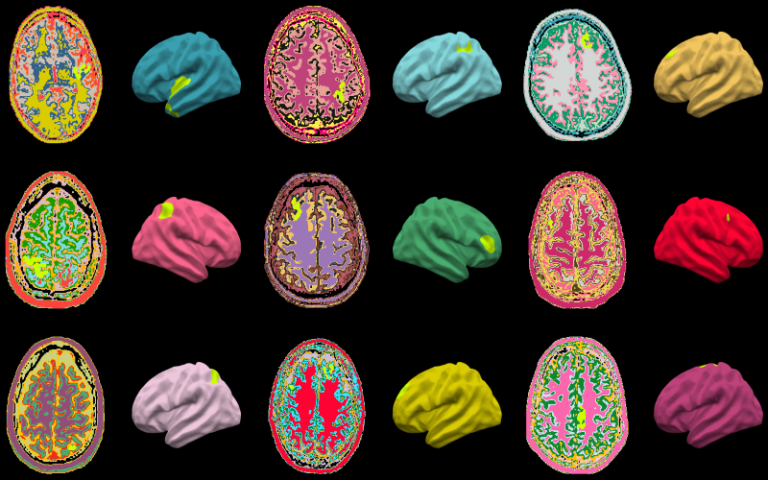
In the medical world, there’s a new application of machine learning-based image analysis in the field of neurology, where researchers at University College London have trained a model to detect early signs of epilepsy-causing brain lesions.
MRIs of brains used to train the UCL algorithm.
One frequent cause of drug-resistant epilepsy is what is known as a focal cortical dysplasia, a region of the brain that has developed abnormally but for whatever reason doesn’t appear obviously abnormal in MRI. Detecting it early can be extremely helpful, so the UCL team trained an MRI inspection model called Multicentre Epilepsy Lesion Detection on thousands of examples of healthy and FCD-affected brain regions.
The model was able to detect two thirds of the FCDs it was shown, which is actually quite good as the signs are very subtle. In fact, it found 178 cases where doctors were unable to locate an FCD but it could. Naturally the final say goes to the specialists, but a computer hinting that something might be wrong can sometimes be all it takes to look closer and get a confident diagnosis.
“We put an emphasis on creating an AI algorithm that was interpretable and could help doctors make decisions. Showing doctors how the MELD algorithm made its predictions was an essential part of that process,” said UCL’s Mathilde Ripart.
A new White House directive will require academic journals to provide immediate access to papers that are publicly funded. Announced Thursday, the policy, which will be phased in over the next several years, will end a rule that had allowed publishers to keep tax-financed publications behind a paywall for 12 months.
Previously, only research funded by federal offices with R&D expenditures of $100 million or more had to be published in open access, as per 2013 White House guidance. The new directive applies to nearly all agencies — about 400 in total, The New York Times estimates — and also requires that publications be made available in “machine-readable” formats to ensure easy reuse.
In recent decades, efforts like Arxiv.org, Cornell’s open repository of research papers that largely haven’t been peer reviewed, have improved access to studies. But a handful of for-profit journals maintain a stranglehold on publication. According to a 2015 report out of the University of Montreal, five corporations control roughly half of all journal articles published. The venture is hugely profitable for the publishers, which charge both for study submission and rights to published works. One top firm, Elsevier, reported just over £2 billion (~$2.35 billion) in revenue in 2010.
But it’s an expensive arrangement for those in the business of buying study access — the University of California system once had an $11 million annual subscription to Elsevier. For researchers in low- and middle-income countries, who often don’t have subscription deals with journal publishers, the situation is even more challenging — so much so that it’s spawned communities like Sci-Hub that provide illicit, free access to journal-published literature.
Publishers argue that they provide a valuable service, justifying with curation the fees that they impose. But not all academics agree. For the most part, journals judge whether works are worth publishing and review basic elements like grammar. However, they don’t pay staffers to evaluate experiments and conduct validity checks — that intensive legwork is left to scientists working on a volunteer basis.
A 2005 Deutsche Bank report referred to it as a “bizarre … triple-pay” system, in which “the state funds most research, pays the salaries of most of those checking the quality of research, and then buys most of the published product.” Government-funded institutions and universities tend to be the largest clients of journal publishers.
As Vox points out in a 2019 feature, U.S. taxpayers spend $140 billion every year supporting research — a huge percentage of which they can’t access for free. Soon, thankfully, that’ll change.
If you ask me, climate tech investor Contrarian Ventures isn’t so contrarian anymore.
The five-year-old firm is targeting $100 million for its second seed-stage fund, and it’s doing so smack in the middle of a climate-tech dealmaking boom. So, if anything, it’s trendy.
But when the seed-stage VC — a backer of e-bike maker Zoomo and solar data firm PVcase — debuted with a $13.6 million fund in 2017, its focus was “obviously contrarian,” founding partner Rokas Peciulaitis told TechCrunch, as the “industries in vogue at the time were AI and Fintech.”
The launch also marked an unexpected pivot for Peciulaitis, who says he dove into the scene with “literally zero climate tech sector experience.” He’d recently left an inflation-trading job at Bank of America, where the work was “not fulfilling in the slightest,” Peciulaitis said in a nod to the bank’s reputation as a major funder of fossil fuels.
In 2017, PitchBook recorded 578 climate tech deals globally, altogether worth $12.5 billion. The sector has since tripled in size, as climate change–driven extreme weather events occupy evermore space in our collective consciousness. To that point: PitchBook tracked 1,130 climate tech deals globally in 2021, topping $44.8 billion in value. Climate tech is cool now, but Peciulaitis’s Lithuania-based venture firm is sticking with its name anyways.
Like any venture capital firm, Contrarian says that it stands out through its emphasis on “developing excellent relationships with founders.” Materially, the firm invests in tech that could help decarbonize transportation, industrial processes, energy and buildings.
Contrarian has completed 21 deals to date, and this year it expanded beyond Lithuania with new partners in Berlin and London. The firm backs emerging startups in Europe as well as Israel, but nowhere else in the Middle East. Currently, the firm does not invest in agriculture-related tech, though the category has a significant carbon footprint of its own.
In an email, Contrarian said it counts London-based tech VC Molten Ventures among its limited partners. The firm declined to share a full list of its LPs, but stated that none of them were fossil fuel companies.
Achieving similar marbling and texture as a cut of animal meat has been a challenge for food technology startups aiming to produce whole cuts of cultivated meat, but Novel Farms believes it has cracked the code with its pork loin.
Armed with $1.4 million in SAFE notes, or simple agreement for future equity, the company, founded by Nieves Martinez Marshall and Michelle Lu in 2020, is making cultivated meat — grown from cells instead of in an animal; they met as postdoctoral scientists in the molecular and cell biology department at the University of California at Berkeley.
Martinez Marshall told TechCrunch it has “successfully cultivated the world’s first slaughter-free pork loin that displays the marbling and texture of a real muscle cut.”
“There’s no other company right now doing pork loin,” she said when asked how the company could make that kind of “world’s first” statement. The closest competitors being Higher Steaks in London and CellX in China, both doing pork belly, she added.
Other cultivated meat companies focus on making food, in most cases from ground sources. For example, sausages (Meatable), burgers (SCiFi Foods) and chicken (UPSIDE Foods), which are easier structures to make than whole cuts, Martinez Marshall added. Bluu Seafood, a German company developing lab-grown seafood, debuted its fish sticks and fish balls this week. The products are made from cultivated fish cells and plant protein.
Novel Farms co-founders Michelle Lu and Nieves Martinez Marshall. Image Credits: Novel Farms
Though Martinez Marshall didn’t want to get into the weeds about Novel Farms’ technology, she explained that it is developing a proprietary microbial fermentation approach to produce the scaffolding needed to create the whole cuts, but in a lower-cost way. It does this by using inexpensive microorganisms commonly used in food.
However, unlike peers in the cultivated meat industry adding biomaterials, like alginate, cellulose and mycelia, for cells to attach themselves to make the meat structure, Novel Farms’ technology is able to completely bypass that step, reducing scaffolding production costs by 99.27%. Martinez Marshall says this means scaling the product will be faster, as will achievement of price parity with traditional meat products.
The company has already demonstrated that its technology is viable and it can make a piece of cultivated meat. Still, she doesn’t expect to get the pork loin into the hands of consumers until 2025, with commercial plants coming online in 2026, followed by mass production in 2027.
The SAFE investment comes from a group of investors, including a majority stake by Big Idea Ventures, and financing from Joyance/Social Starts, Sustainable Food Ventures, Good Startup, CULT foods and strategic angel investors. Novel Farms is also starting a seed round.
Plans for the capital include hiring a team (currently it is just Martinez Marshall and Lu) and scaling.
“We just have a very good, efficient scaffold, and the cells attach very well,” Martinez Marshall said. “That’s something that nobody else has. Once we confirm and scale with a bioreactor, then we will be the most affordable of all the companies.”
Back in 2019, Google proudly announced that they had achieved what quantum computing researchers had sought for years: proof that the esoteric technique could outperform traditional ones. But this demonstration of “quantum supremacy” is being challenged by researchers claiming to have pulled ahead of Google on a relatively normal supercomputer.
To be clear, no one is saying Google lied or misrepresented its work — the painstaking and groundbreaking research that led to the quantum supremacy announcement in 2019 is still hugely important. But if this new paper is correct, the classical vs. quantum computing competition is still anybody’s game.
It sounds like a cop-out, but the point of quantum supremacy is to show the method’s viability by finding even one highly specific and weird task that it can do better than even the fastest supercomputer. Because that gets the quantum foot in the door to expand that library of tasks. Perhaps in the end all tasks will be faster in quantum, but for Google’s purposes in 2019, only one was, and they showed how and why in great detail.
Now, a team at the Chinese Academy of Sciences led by Pan Zhang has published a paper describing a new technique for simulating a quantum computer (specifically, certain noise patterns it puts out) that appears to take a tiny fraction of the time estimated for classical computation to do so in 2019.
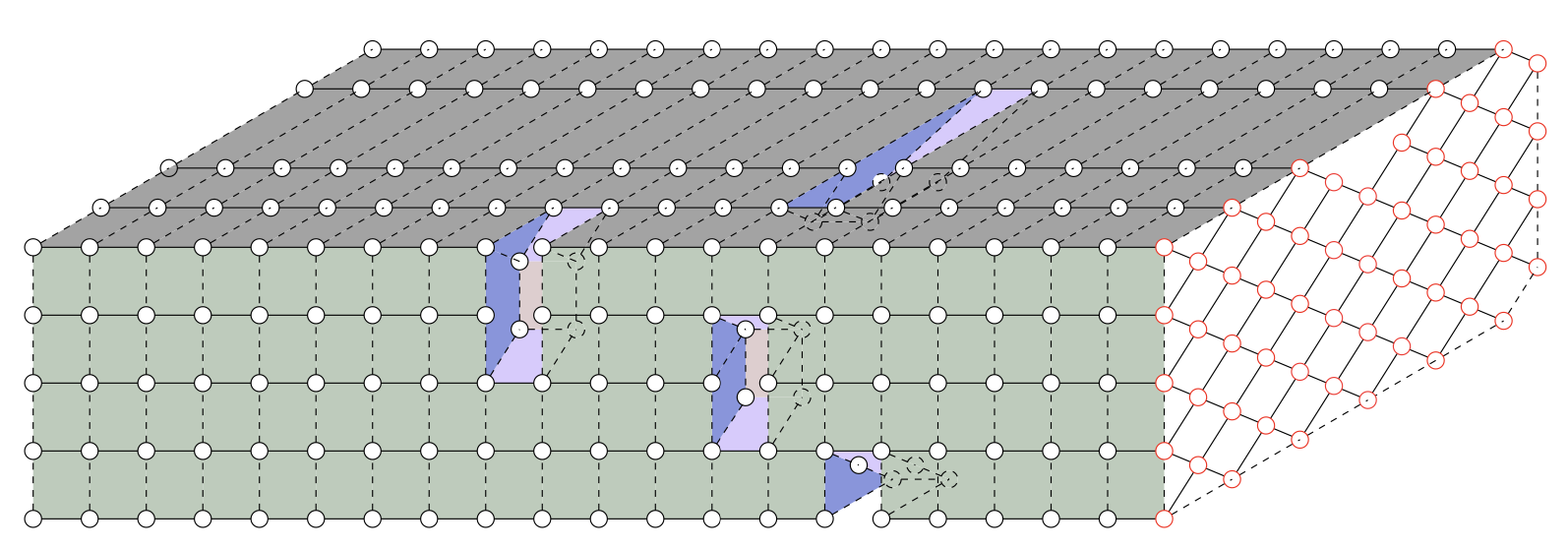
Not being a quantum computing expert nor a statistical physics professor myself, I can only give a general idea of the technique Zhang et al used. They cast the problem as a large 3D network of tensors, with the 53 qubits in Sycamore represented by a grid of nodes, extruded out 20 times to represented the 20 cycles the Sycamore gates went through in the simulated process. The mathematical relationships between these tensors (each its own set of interrelated vectors) was then calculated using a cluster of 512 GPUs.
An illustration from Zhang’s paper showing a visual representation of the 3D tensor array they used to simulate Sycamore’s quantum operations.
In Google’s original paper, it was estimated that performing this scale of simulation on the most powerful supercomputer available at the time (Summit at Oak Ridge National Laboratory) would take about 10,000 years — though to be clear, that was their estimate for 54 qubits doing 25 cycles. 53 qubits doing 20 is considerably less complex but would still take on the order of a few years by their estimate.
Zhang’s group claims to have done it in 15 hours. And if they had access to a proper supercomputer like Summit, it might be accomplished in a handful of seconds — faster than Sycamore. Their paper will be published in the journal Physical Review Letters; you can read it here (PDF).
These results have yet to be fully vetted and replicated by those knowledgeable about such things, but there’s no reason to think it’s some kind of error or hoax. Google even admitted that the baton may be passed back and forth a few times before supremacy is firmly established, since it’s incredibly difficult to build and program quantum computers while classical ones and their software are being improved constantly. (Others in the quantum world were skeptical of their claims to begin with, but some are direct competitors.)
As University of Maryland quantum scientist Dominik Hangleiter told Science, this isn’t a black eye for Google or a knockout punch for quantum in general by any means: “The Google experiment did what it was meant to do, start this race.”
Google may well strike back with new claims of its own — it hasn’t been standing still either — and I’ve contacted the company for comment. But the fact that it’s even competitive is good news for everyone involved; this is an exciting area of computing and work like Google’s and Zhang’s continues to raise the bar for everyone.