Breakthrough Energy Ventures, a climate-focused VC firm linked to some of Earth’s wealthiest individuals, has joined a $44 million bet on solar startup Terabase Energy.
Terabase aims to rapidly build new solar farms “at the terawatt scale,” CEO Matt Campbell said in a statement. The startup claims its automated, on-site factory can already speed up plant construction and cut costs by employing robotic arms that lift and connect heavy solar panels to sun trackers. When asked for photos of the insides of its factory, Campbell pointed TechCrunch to previously published aerial pics and declined to share more, “for competitive reasons.”
Terabase also makes software tools to manage the design and construction of solar farms. The startup recently wrapped its first commercial project, where its robots reportedly installed 10 megawatts worth of panels. There are one million megawatts in a terawatt, so the startup still has a long way to go to reach its aspirations.
Breakthrough Energy Ventures was founded by Bill Gates, and its board members include Jeff Bezos and Masayoshi Son. The VC firm co-led the Terabase deal alongside Lime and Amp Robotics investor Prelude Ventures.
Their investment comes as rich folks face scrutiny for their outsized climate pollution. Gates’ private jet might not be as active as Taylor Swift’s, yet the Microsoft co-founder reportedly owns several and has called private flying his “guilty pleasure.”
Other recent deals for solar energy startups include panel installer Zolar ($105 million) and solar network developer Okra ($2.1 million).
Like a groundhog and its shadow, many venture capitalists see a shrinking economy and burrow away, resting their check-signing hand for better days.
But climate-focused VCs are on a hot streak lately, pumping well over a billion dollars per quarter into startups that strive to mitigate emissions as the Earthbakes.
Buoyant Ventures is one such firm building momentum for the sector. Based in Chicago, the investor told regulators this week via an SEC filing that it has locked down just over $50 million for a new fund. Buoyant declined to comment when emailed by TechCrunch, but the filing shows the firm had been raising cash for the fund since at least May 2021. So far, 75 (unnamed) limited partners have chipped in, and Buoyant is fishing for just shy of $50 million more.
Led by Electronic Arts and Energize Ventures alum Amy Francetic and former Accenture executive Allison Myers, Buoyant’s first deal dates back to the summer of 2020. That’s when it backed Raptor Maps, which aims to help solar farms squeeze more juice from the sun by spotting issues—like panel damage and shading—via drones and sensors.
Buoyant said in 2021 that it’s focused on “solutions for the industries contributing the most to carbon emissions,” including power, transportation, agriculture and buildings. Since then, it has funded at least four other early-ish stage startups, including FloodFlash, StormSensor and others seeking to cash in on emissions mitigation or climate adaptation.
Several other noteworthy climate (and climate-adjacent) VC fundraises have crossed our desks in recent weeks, including Fifth Wall‘s $500 million fund, Climentum Capital ($157 million), Systemiq Capital ($70 million) and Equal Ventures ($56 million).
NASA’s Landsat satellites have consistently made history in Earth observation since the project’s first launch in 1972, with this year marking 50 years of innovation and science. Its influence may surprise you, as will its continued relevance in the face of a fast-growing commercial imaging satellite sector.
Landsat may be a familiar name to you but doesn’t ring any particular bells. It’s understandable — there are a ton of NASA satellites up there looking down on the planet. But the easiest way to say it is this: In 1972, Landsat basically invented modern Earth observation. Then, remember a while back when every Google Earth image said “USGS” on it? Yeah, that was Landsat too. The project has basically ushered satellite imaging from bleeding edge research tool to everyday technology.
Landsat 9 just launched last September, the latest in a long line of influential spacecraft.
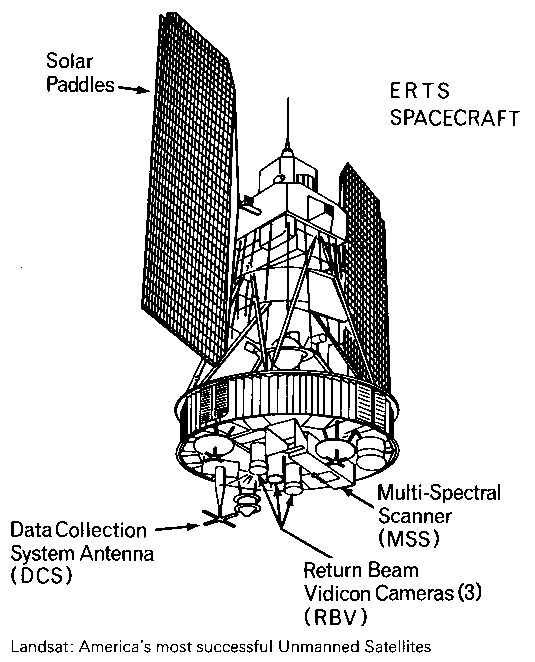
A schematic sketch of Landsat-1. Image Credits: NASA
I talked with Jim Irons, who has worked at NASA since 1978 and on Landsat since 1992. Irons told the story of Landsat from the beginning, both what he took part in himself and the lore he’s absorbed over the years. It’s fitting that for a project that would redefine Earth imaging, its very first satellite was both innovative and historically significant.
“Landsat 1 launched in 1972 — it carried two instruments, one was the Return Beam Vidicon, and it was kind of like a TV camera, it took analog data,” Irons said. “But Hughes [Aircraft Company] convinced NASA to put another instrument on the payload that was more experimental: the Multi-Spectrum Scanner. And it provided digital data.”
It hardly needs to be said that in 1972, digital anything was pretty innovative, let alone high-performance digital sensors in orbit. But the team clearly saw the writing on the wall, and good thing too.
“After launch, the RBV had problems, and the data from the MSS became the preferred data. That was a big turning point,” recalled Irons. “It was an instrument that used an oscillating mirror that went back and forth to scan a path at 7-14 Hz, underneath the orbital path of the sensor, to create a digital image. And it’s mechanical! It was amazing.”
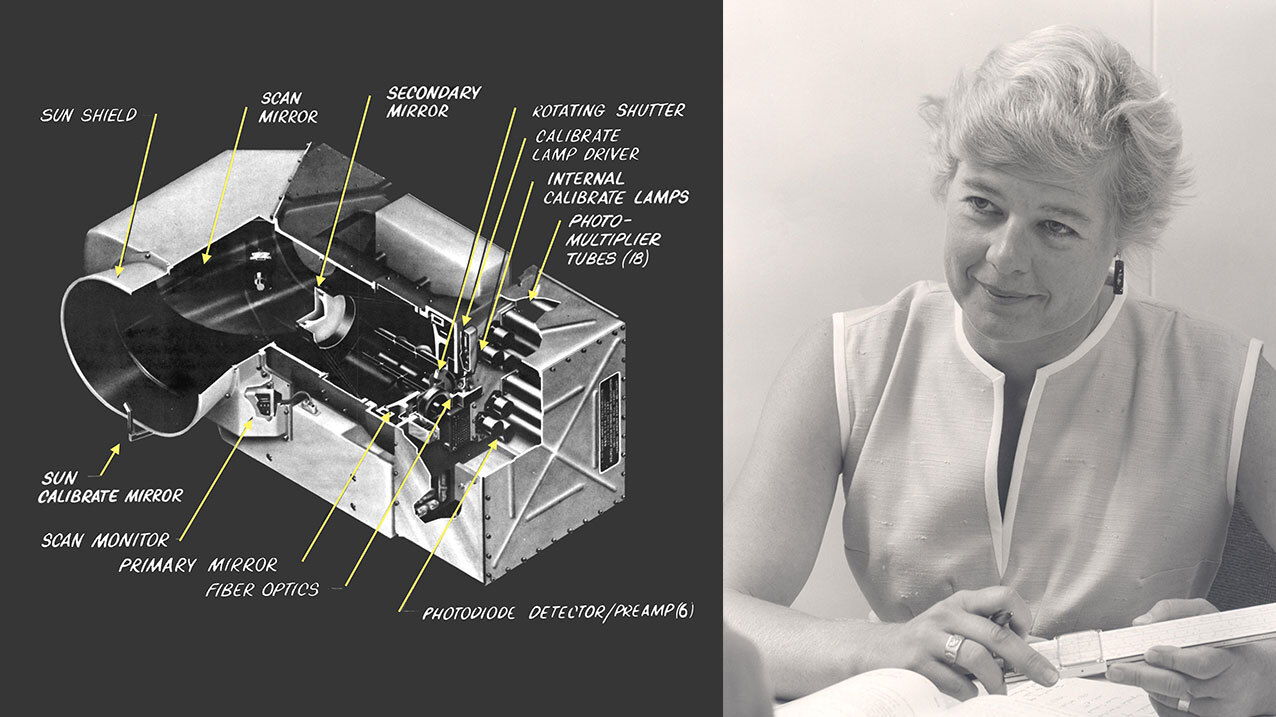
“The designer of this sensor, Virginia Norwood, she’s still with us, in her 90s. It was very unusual at the time to have a female engineer at all. She came to the launch of Landsat 9 last month, actually.”
Virginia Norwood (photo taken in 1972) with the MSS instrument she created. Image Credits: NASA
It’s a remarkable fact that the beginning of the orbital imaging revolution was the brainchild of one of the then-rare women in the space and tech industries, whose roles in many of the era’s important accomplishments have only recently begun to be given the attention they deserve. You can read more about Norwood’s role in the creation of the MSS, which is the precursor to many more such systems, at this NASA history article, or this more recent piece.
A successor to the MSS called the Thematic Mapper launched in 1982 with more spectral bands, but then in 1984 another big improvement struck a nerve at HQ:
“Landsat 5 in 1984 carried both a multispectral scanner and advancement on the thematic mapper idea that improved the spatial resolution of the data, from what had been 80 meters with the MSS to 30 meters, and spectral bands were added,” Irons said. “But there was all this data! Some people were afraid of that data, that analysts would be overwhelmed by it — but it didn’t turn out that way. Computer capacities kept up and soon the thematic mapper data was preferred.”
Image Credits: NASA
That would prove a rule as time went on and right up until the present: There really is no such thing as too much data. As long as you can collect it and store it, someone will find a use for it.
They might even pay you for it — but an attempt to privatize Landsat in the following years fell flat, or burned up on reentry in the case of Landsat 6, which never made it to orbit. Meanwhile, the private company created to operate and distribute the rest of the data jacked up the price until no one was willing to pay any more. “It was up to $4,400 per scene of thematic mapper data. People just stopped using it,” Irons said.
When NASA and the USGS, which handled the distribution of the imagery originally, returned to the reins, they had an international data recovery problem. Imagine having reams of data in a ground station in China or South America, long before ubiquitous broadband networks. How do you get it back to HQ in the States for central processing and analysis? I told Irons I was picturing big trucks full of hard drives, the internal combustion equivalent of Sneakernet.
“That’s exactly what happened!” he laughed. “They just drove up to the [USGS] facility with semi truck trailers full of magnetic tapes. It was difficult because they had all these different formats and instruments. So that created a little chaos. They bought pizza ovens to bake the water out of some of those tapes.” (I wanted to hear more about that part but our time was limited.)
Image Credits: NASA
But the repatriation of the data was only a precursor to an even larger shift.
“After Landsat 7 launched was perhaps the biggest change in the entire program,” Irons said. “USGS was still charging $600 for a mapper scene of data. And they made made what I consider an institutionally brave decision in 2008, to be consistent with NASA and provide Landsat data at no cost to anyone who wanted it. So it went from $400 to $600 to free.”
As you can imagine, this choice completely upended the model, and overnight, it changed everything.
“There was an explosion of use and redistribution of the data,” he continued. “Now, some places like Google Earth and Amazon Cloud Services, they’d gone in and downloaded the whole archive from USGS.”
Remember the old Google Earth app? Image Credits: Google
That’s why for years, whenever you looked at an online map, it credited the USGS. Of course Google and Amazon didn’t own the imagery, or capture it themselves, though now all the majors are doing that at various scales. They simply downloaded a huge picture of the entire Earth and re-served it to their customers in a new form.
“It’s a struggle for us to brand the data and the program so taxpayers know they’re getting their money’s worth,” admitted Irons. It’s not like every time you opened Google Maps, it thanked you for making their business possible!
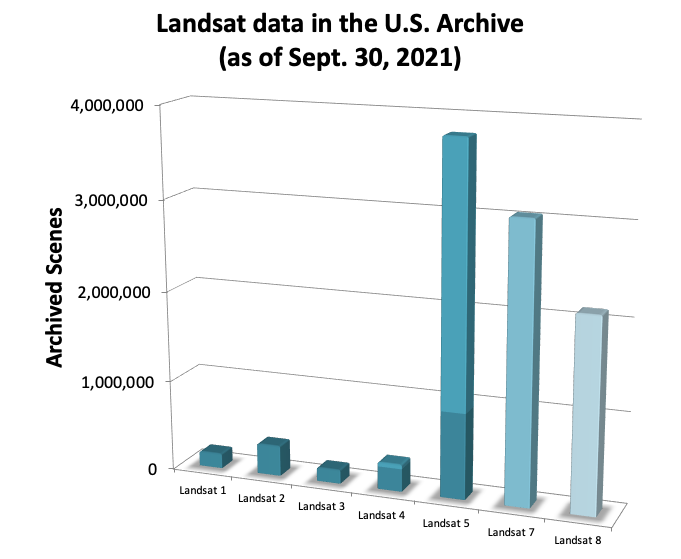
In the years since, Landsat 8 and 9 have launched with improved sensors and continued to collect invaluable data that is continuous with the previous decades — a free, long-term database of a large portion of the planet imaged every couple weeks or so depending on the era.
Image Credits: NASA
Of course nowadays constellations like Planet’s are imaging the whole globe on a daily basis. So why have Landsat at all?
“Those of us who work on Landsat are very impressed by what the commercial providers have achieved,” Irons said. “The message we want to get out is that Landsat is complementary to that data — they don’t replace Landsat data. One, it’s open and transparent access — that’s key, and it’s true of all the data collected by NASA satellites.
“Two, the USGS has maintained this 50-year archive of data. Is there a business case for companies to archive their data for decades, so we can observe the effects of climate change over the long term rather than just have short bursts of data? I don’t know that the business case is there.”
You can see an example of what decades of continuous data looks like here:
“And one of the things that enables our time series analyses is that NASA pays a great deal of attention to inter-sensor calibration,” Irons continued. “If you’re going from one Landsat image to another, you know it’s been calibrated — if you see a change over time, you can be clear that the thing is changing rather than the camera. [Commercial constellations] use Landsat data to do that; we serve as an industry standard to help them do their calibration.”
Here the conversation overlapped with what I talked about with Ginger Butcher, who’s done outreach for the project for years.
“We can compare a Landsat image today to a Landsat image from 1972,” she said. “That’s one of the tenets of the program: We have a dedicated calibration team keeping an eye on the instruments. Every full moon we turn the spacecraft around to use it as a kind of photographer’s grey card.”
With the increasing prominence of commercial providers in the U.S. space program, it was a real question over the last few years whether Landsat was worthwhile to continue funding, but arguments like those above won out.
“We used to have to work really hard to get that next mission, but now we’ve basically got the government saying this is a valuable resource worth continuing with,” Butcher said. “Now we’re looking to the future and what kind of capabilities we want to get out of the next Landsat. What kind of research are people doing? What additional wavelengths are needed for work on ice, or on forests, or particular areas in agriculture? For example, with thermal data we can look at crops and see if they’re being overwatered or underwatered — with water rights out west, that’s really important. As scientists take on new questions and new areas of study, they decide where Landsat goes next.”
More than ever, the project will work collaboratively with the commercial sector and with ESA satellites like Sentinel-2.
“We think it’s great,” said Irons. “The emergence of all these systems means the Landsat project has been incredibly successful; it basically created the market for them.”
World Fund, a newcomer in climate-VC land, is taking the lead in a $128 million round for IQM, with hopes the Finnish quantum computing company will one day deliver carbon cuts by the megatonne.
Quantum computing trades the bits of conventional computers for quantum bits, and in theory, quantum machines may be better suited for solving some highly complex problems in fields like chemistry and machine learning. IQM argues its tech could also move the needle on climate, but there is cause to be skeptical of the industry on the whole; we’ve seen a lot of hype around quantum computing startups, and yet the field mostly remains stuck in labs today.
Still, IQM projects its quantum computers will help mitigate greenhouse gas emissions in as soon as the next three to five years “for some of the early use-cases.” The company says it is already “working on novel approaches to develop better battery solutions with a leading car manufacturer,” and it plans to spend its new funds on further research in battery tech, quantum chemistry and other areas. IQM cautioned in an email to TechCrunch that “scientific breakthroughs don’t follow a set timeline.”
The idea of applying quantum tech to climate change mitigation apparently isn’t all that far-fetched. Microsoft Azure CTO Mark Russinovich said in an email to TechCrunch that he “[believes] quantum computing can help with climate change, specifically with the carbon capture challenge (carbon fixation).” Microsoft’s research includes digging into how quantum computing can uncover “more efficient” ways to convert carbon dioxide into other chemical compounds.
World Fund and IQM’s other investors have also implicitly endorsed the idea via their checkbooks. In a statement, the German VC said it exclusively backs tech with the potential to remove “100 million tonnes” — that is, 100 megatonnes — “of carbon from the atmosphere yearly by 2040.” Other investors in the latest round include the EU’s European Innovation Council and Tencent. The deal brings IQM’s post-money valuation near the $1 billion mark, a person familiar with the matter told TechCrunch.
Some quantum computing companies have faced accusations of exaggerating their progress. Maryland-based IonQ has talked up its advances in quantum computing, but activist investor Scorpion Capital recently accused the company of fraud, calling its tech a “useless toy that can’t even add 1+1.” IonQ’s founders pushed back on the accusations, saying they were “amused at the extreme level of ignorance behind this attack.” In a related field, former staffers at British quantum encryption company Arqit reportedly questioned the usefulness and maturity of its quantum tech.
Crop One Holdings and Emirates Flight Catering announced this week they opened Emirates Crop One, what they say is “the world’s largest vertical farm.”
The over 330,000-square-foot facility is located in Dubai, United Arab Emirates near Al Maktoum International Airport at Dubai World Central. It has the capacity to produce over 2 million pounds of leafy greens annually.
The facility got its start in 2018 when Crop One, an indoor vertical farming company, and Emirates Flight, the airline Emirates catering arm, signed a $40 million joint venture to build Emirates Crop One. AgFunder reported the $40 million was a majority debt-funded.
Dubbed ECO 1, the farm uses 95% less water than field-grown produce and is guaranteed an output of three tons per day, according to the companies. Passengers on Emirates and other airlines will be able to eat the leafy greens, which include lettuces, arugula, mixed salad greens, and spinach, on their flights starting this month.
Those local to the United Arab Emirates will be able to buy the produce at stores under the Bustanica brand. The greens require no pre-washing and are grown without pesticides, herbicides or chemicals.
“We are proud to bring Crop One’s best-in-class technology to this innovative food production facility alongside our joint venture partner,” said Craig Ratajczyk, CEO at Crop One., in a written statement.” ECO 1 will address growing supply chain challenges and food security issues, while introducing millions of new consumers to the benefits of vertically farmed produce. It’s our mission to cultivate a sustainable future to meet global demand for fresh, local food, and this new farm is the manifestation of that commitment. This new facility serves as a model for what’s possible around the globe.”
This is Crop One’s second vertical farm after its flagship facility in Millis, Massachusetts.
Emirates Crop One joins vertical farms being built all over the world. In May, Bowery Farms opened its vertical farm in Pennsylvania. Though it did not give a size for the facility, my colleague Brian Heater wrote that it was suspected to be 156,000 square feet. Earlier this year, Upward Farms was planning a 250,000-square-foot vertical farm, also in Pennsylvania, that was poised to open in mid-2023.
It felt like for a long time, the quantum computing industry avoided talking about ‘quantum advantage’ or ‘quantum supremacy,’ the point where quantum computers can solve problems that would simply take too long to solve on classical computers. To some degree, that’s because the industry wanted to avoid the hype that comes with that, but IBM today brought back talk about quantum advantage again by detailing how it plans to use a novel error mitigation technique to chart a path toward running the increasingly large circuits it’ll take to reach this goal — at least for a certain set of algorithms.
It’s no secret that quantum computers hate nothing more than noise. Qubits are fickle things, after all, and the smallest change in temperature or vibration can make them decohere. There’s a reason the current era of quantum computing is associated with ‘noisy intermediate-scale quantum (NISQ) technology.
The engineers at IBM and every other quantum computing company are making slow but steady strides toward reducing that noise on the hardware and software level, with IBM’s 65-qubit systems from 2020 now showing twice the coherence time compared to when they first launched, for example. The coherence time of IBM’s transmon superconducting qubits is now over 1ms. That may not sound like much — and some other companies have shown
But IBM is also taking another approach but betting on new error mitigation techniques, dubbed probabilistic error cancellation and zero noise extrapolation. At a very basic level, you can almost think of this as the quantum equivalent of the active noise cancellation in your headphones. The system regularly checks the system for noise and then essentially inverts those noisy circuits to enable it to create virtually error-free results.
IBM has now shown that this isn’t just a theoretical possibility but actually works in its existing systems. One disadvantage here is that there is quite a bit of overhead when you constantly sample these noisy circuits and that overhead is exponential in the number of qubits and the circuit depths. But that’s a tradeoff worth making, argues Jerry Chow, the Director of Hardware Development for IBM Quantum.
“Error mitigation is about finding ways to deal with the physical errors in certain ways, by learning about the errors and also just running quantum circuits in such a way that allows us to cancel them,” explained Chow. “In some ways, error correction is like the ultimate error mitigation, but the point is that there are techniques that are more near term with a lot of the hardware that we’re building that already provide this avenue. The one that we’re really excited about is called probabilistic error cancellation. And that one really is a way of trading off runtime — trading off running more circuits in order to learn about the noise that might be inherent to the system that is impacting your calculations.”
The system essentially inserts additional gates into existing circuits to sample the noise inherent in the system. And while the overhead increases exponentially with the size of the system, the IBM team believes it’s a weaker exponential than the best classical methods to estimate those same circuits.
As IBM previously announced, it plans to introduce error mitigation and suppression techniques into its Qiskit Runtime by 2024 or 2025 so developers won’t even have to think about these when writing their code.
Research in the field of machine learning and AI, now a key technology in practically every industry and company, is far too voluminous for anyone to read it all. This column, Perceptron, aims to collect some of the most relevant recent discoveries and papers — particularly in, but not limited to, artificial intelligence — and explain why they matter.
In this batch of recent research, Meta open-sourced a language system that it claims is the first capable of translating 200 different languages with “state-of-the-art” results. Not to be outdone, Google detailed a machine learning model, Minerva, that can solve quantitative reasoning problems including mathematical and scientific questions. And Microsoft released a language model, Godel, for generating “realistic” conversations that’s along the lines of Google’s widely publicized Lamda. And then we have some new text-to-image generators with a twist.
Meta’s new model, NLLB-200, is a part of the company’s No Language Left Behind initiative to develop machine-powered translation capabilities for most of the world’s languages. Trained to understand languages such as Kamba (spoken by the Bantu ethnic group) and Lao (the official language of Laos), as well as over 540 African languages not supported well or at all by previous translation systems, NLLB-200 will be used to translate languages on the Facebook News Feed and Instagram in addition to the Wikimedia Foundation’s Content Translation Tool, Meta recently announced.
AI translation has the potential to greatly scale — and already has scaled– the number of languages that can be translated without human expertise. But as some researchers have noted, errors spanning incorrect terminology, omissions, and mistranslations can crop up in AI-generated translations because the systems are trained largely on data from the internet — not all of which is high-quality. For example, Google Translate once presupposed that doctors were male while nurses were female, while Bing’s translator translated phrases like “the table is soft” as the feminine “die Tabelle” in German (which refers a table of figures).
For NLLB-200, Meta said it “completely overhauled” its data cleaning pipeline with “major filtering steps” and toxicity-filtering lists for the full set of 200 languages. It remains to be seen how well it works in practice, but — as the Meta researchers behind NLLB-200 acknowledge in an academic paper describing their methods — no system is completely free of biases.
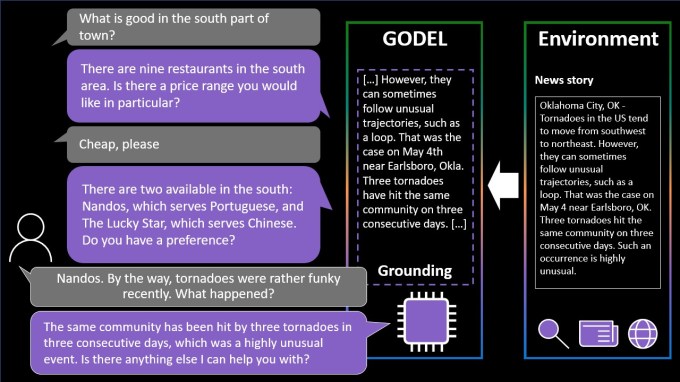
Godel, similarly, is a language model trained on a vast amount of text from the web. However, unlike NLLB-200, Godel was designed to handle “open” dialogue — conversations about a range of different topics.
Image Credits: Microsoft
Godel can answer a question about a restaurant or have a back-and-forth dialogue about a particular subject, such as a neighborhood’s history or a recent sports game. Usefully, and like Google’s Lamda, the system can draw on content from around the web that wasn’t a part of the training data set, including restaurant reviews, Wikipedia articles, and other content on public websites.
But Godel encounters the same pitfalls as NLLB-200. In a paper, the team responsible for creating it notes that it “may generate harmful responses” owing to the “forms of social bias and other toxicity” in the data used to train it. Eliminating, or even mitigating, these biases remains an unsolved challenge in the field of AI — a challenge that might never be completely solved.
Google’s Minerva model is less potentially problematic. As the team behind it describes in a blog post, the system learned from a data set of 118GB scientific papers and web pages containing mathematical expressions to solve quantitative reasoning problems without using external tools like a calculator. Minerva can generate solutions that include numerical calculations and “symbolic manipulation,” achieving leading performance on popular STEM benchmarks.
Minerva isn’t the first model developed to solve these types of problems. To name a few, Alphabet’s DeepMind demonstrated multiple algorithms that can aid mathematicians in complex and abstract tasks, and OpenAI has experimented with a system trained to solve grade school-level math problems. But Minerva incorporates recent techniques to better solve mathematical questions, the team says, including an approach that involves “prompting” the model with several step-by-step solutions to existing questions before presenting it with a new question.
Image Credits: Google
Minerva still makes its fair share of mistakes, and sometimes it arrives at a correct final answer but with faulty reasoning. Still, the team hopes that it’ll serve as a foundation for models that “help push the frontiers of science and education.”
The question of what AI systems actually “know” is more philosophical than technical, but how they organize that knowledge is a fair and relevant question. For example, an object recognition system may show that it “understands” that housecats and tigers are similar in some ways by allowing the concepts to overlap purposefully in how it identifies them — or maybe it doesn’t really get it and the two types of creatures are totally unrelated to it.
Researchers at UCLA wanted to see if language models “understood” words in that sense, and developed a method called “semantic projection” that suggests that yes, they do. While you can’t simply ask the model to explain how and why a whale is different from a fish, you can see how closely it associates those words with other words, like mammal, large, scales, and so on. If whale associates highly with mammal and large but not with scales, you know it’s got a decent idea of what it’s talking about.
An example of where animals fall on the small to large spectrum as conceptualized by the model.
As a simple example, they found animal coincided with the concepts of size, gender, danger, and wetness (the selection was a bit weird) while states coincided with weather, wealth, and partisanship. Animals are nonpartisan and states are genderless, so that all tracks.
There’s no surer test right now as to whether a model understands some words than asking it to draw them — and text-to-image models keep getting better. Google’s “Pathways Autoregressive Text-to-Image” or Parti model looks to be one of the best yet, but it’s difficult to compare it to the competition (DALL-E et al.) without access, which is something few of the models offer. You can read about the Parti approach here, at any rate.
One interesting aspect of the Google write-up is showing how the model works with increasing numbers of parameters. See how the image improves gradually as the numbers increase:
The prompt was “A portrait photo of a kangaroo wearing an orange hoodie and blue sunglasses standing on the grass in front of the Sydney Opera House holding a sign on the chest that says Welcome Friends!”
Does this mean the best models will all have tens of billions of parameters, meaning they’ll take ages to train and run only on supercomputers? For now, sure — it’s sort of a brute force approach to improving things, but the “tick-tock” of AI means that the next step isn’t to just make it bigger and better, but to make it smaller and equivalent. We’ll see who manages to pull that off.
Not one to be left out of the fun, Meta also showed off a generative AI model this week, though one that it claims gives more agency to artists using it. Having played with these generators a lot myself, part of the fun is seeing what it comes up with, but they frequently come up with nonsensical layouts or don’t “get” the prompt. Meta’s Make-A-Scene aims to fix that.
Animation of different generated images from the same text and sketch prompt.
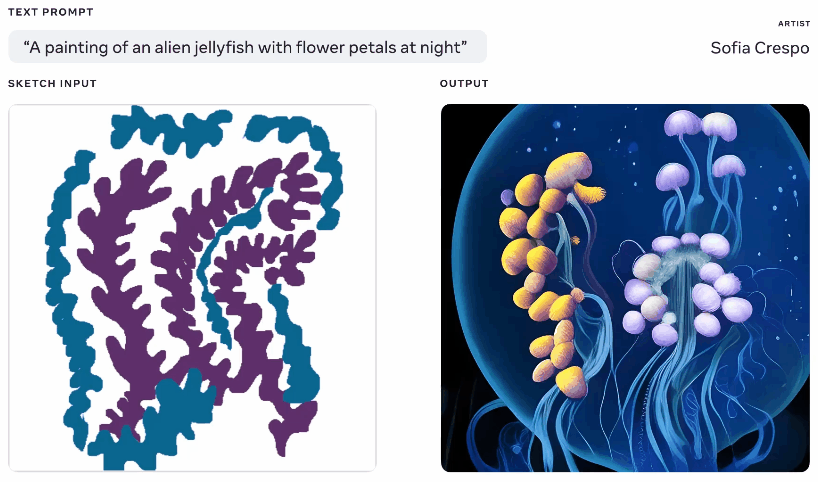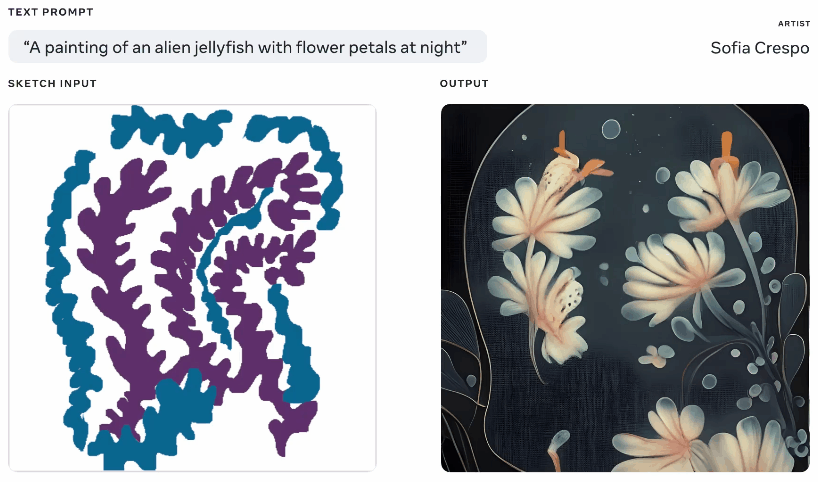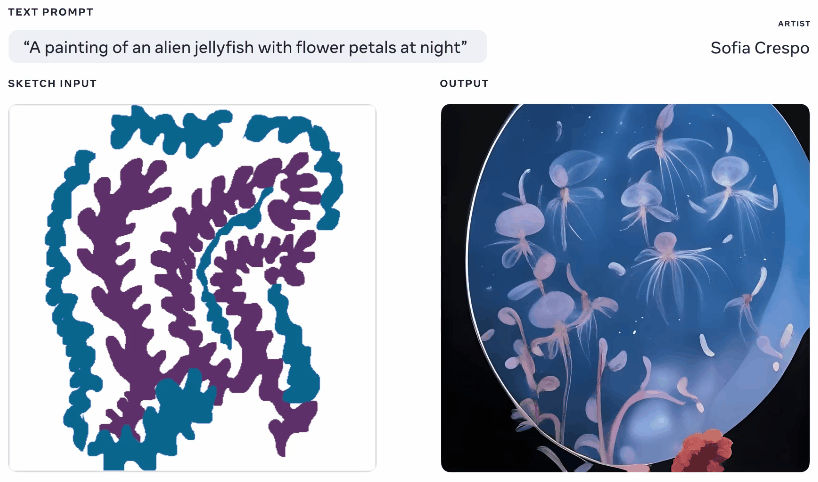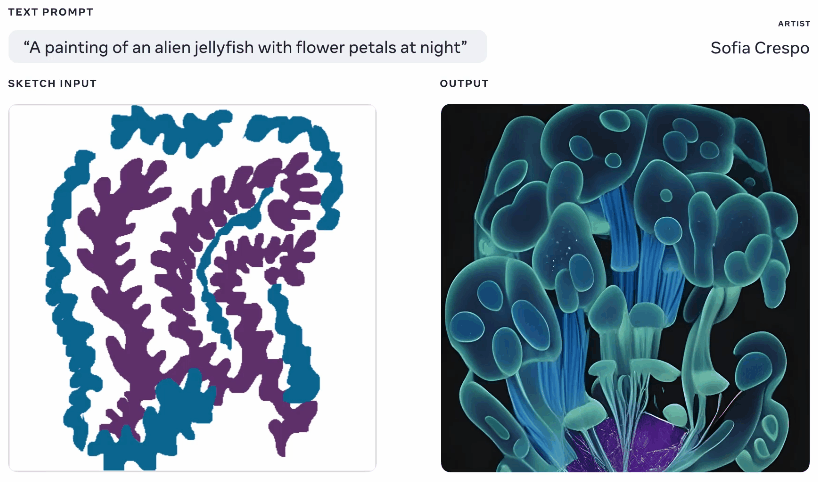
It’s not quite an original idea – you paint in a basic silhouette of what you’re talking about and it uses that as a foundation for generating an image on top of. We saw something like this in 2020 with Google’s nightmare generator. This is a similar concept but scaled up to allow it to create realistic images from text prompts using the sketch as a basis but with lots of room for interpretation. Could be useful for artists who have a general idea of what they’re thinking of but want to include the model’s unbounded and weird creativity.
Like most of these systems, Make-A-Scene isn’t actually available for public use, since like the others it’s pretty greedy computation-wise. Don’t worry, we’ll get decent versions of these things at home soon.
Citing “disturbing” levels of power used by cryptocurrency miners, a group of Democrats led by Sen. Elizabeth Warren is urging the Environmental Protection Agency and the Department of Energy to crack down on the controversial industry.
The letter, signed by four senators and two representatives, calls on regulators to compel cryptominers to disclose their carbon emissions and energy use. Environmentalists have long raised concerns about Bitcoin and other power-hungry, proof-of-stake tokens — and globally, cryptocurrencies are estimated to consume more energy than entire countries, such as Venezuela and Finland.
In the U.S., just seven firms have built more than 1.045 gigawatts of capacity for cryptomining purposes, the report states. “This is enough capacity to power all the residences in Houston, Texas.” The mining farms highlighted in the report are run by Stronghold, Greenidge, Bit Digital, Bitfury, Bitdeer, Marathon and Riot.
Though the crypto winter of 2022 might incentivize some miners to scale back operations, the lawmakers argue the industry at large is poised to grow rapidly and “is likely to be problematic for energy and emissions.” Still, they caution that “little is known about the full scope of cryptomining activity.” Hence their call for more data.
In response to the lawmakers, the companies downplayed the industry as a source of planet-cooking emissions. Nevertheless, they highlighted their individual efforts to curtail emissions and tap into renewable sources.
Marathon pointed to its work “with energy companies to build clean, green, renewable energy resources (e.g., solar and wind) that might not otherwise be built.” However, most of the energy tapped by Marathon currently comes from a coal-burning plant in Hardin, Montana.
Along similar lines, Riot argued that “Bitcoin mining drives more demand for renewable energy than the typical U.S. energy consumer” and spotlighted its use of hydroelectricity in upstate New York. Riot’s operations in Rockdale, Texas, however, feature nearly seven times the capacity and draw power from the state grid. Texas generated most of its energy from nonrenewable sources last year (51% from natural gas and 13.4% from coal).
Speaking of coal, Stronghold told lawmakers that it is “actively working to remediate coal refuse piles and converting coal refuse into energy.” Coal mining waste is an environmental nightmare, and cleaning it up is a good idea. Burning coal waste, on the other hand, still yields harmful emissions, though scrubbers can lessen the worst effects.
Blockfusion and Bitdeer, meanwhile, pointed to their use of software to minimize strain on energy grids.
Though the letter casts a critical eye on crypto, the majority of near-term emissions cuts in the U.S. need to come from the power and transportation sectors in order for the U.S. to reach its 2030 net emissions goal, according to researchers at the Electric Power Research Institute. In April last year, the White House said it aimed to halve U.S. greenhouse gas emissions by 2030.
D.C. remains virtually deadlocked on climate legislation, yet Democratic lawmakers (those not named, Sen. Joe Manchin) have sought to curtail emissions via tax credits, which could juice both renewable energy generation and electric car sales. In a June interview with TechCrunch, Energy Secretary Jennifer Granholm said passing clean-energy tax credits this summer was “the most certain path” for the U.S. to follow.
Nucleus Genomics, a genetic testing company focused on calculating a patient’s risk of certain diseases, is adding $14 million on to their initial seed funding round. With this round the company has raised, in total, $17.5 million.
This “seed plus” funding round was led by Alexis Ohanian’s 776. Ohanian is joining investors like Founders Fund, Adrian Aoun (CEO at Forward Health), Brent Saunders (former CEO at Allergan), Matteo Franceschetti (CEO at Eight Sleep), and others. Nucleus originally announced a $3.5 million seed round back in December of 2021.
Typically, Nucleus users will upload their own genetic results previously obtained by an at-home testing company like 23andMe or Ancestry. Then Nucleus will calculate polygenic risk scores, which is a measure that provides a genetic predisposition for a potential condition, and provide information about said risk on their platform. Customers also have the option of ordering their own genetic testing kit provided by the company.
Polygenic risk scores have been scrutinized for their potential bias. In a study published in the National Library of Medicine, close to 80% of participants in genetic studies (and the base of evaluation) have been from European descent, and does not account for demographic differences, like race.
“In genetics, they’re so European biased, so when we actually build models we want to make sure the models work for everyone, not just the United States, or anything out there,” said founder and CEO Kian Sadeghi.
Although Nucleus allows users to upload their genetic info obtained by a third-party, Sadeghi said there is “no need for a formal partnership” with those companies.
Up to now the company has been “focused on assessing risk”, but funds from this round will be used to grow their current team across different areas. Additionally, the company will be establishing their own genetic testing infrastructure and buying testing kits in bulk.
Sadeghi added, he wants (and will allow) users to be in the most control of their data.
When a user signs up on the platform they are asked how they would like their data to be shared, if even, in addition to providing the option to if users would like to provide data to research groups to “advance research and medicine” according to the company.
“Nucleus believes very much in kind of a foundational data ownership and control,” Sadeghi said. “We are built in our DNA, so to speak, on maximal data ownership, and data control. You decide if your data is shared, and if so with who, when and how.”
However, the company has yet to launch mainstream and it is unclear how this will look for users on the company’s platform.
The company suggested in an interview with TechCrunch there would be a possibility they expand into an international market, and for Sadeghi he said it aligns with the vision he’s had since day one.
“When we say human genome and every smartphone, we’re not kidding,” Sadeghi said. “We really see a world beyond just the boundaries of the United States where people can engage and interact and take agency over their health.”
In the creation of a new drug, there comes a point where you have to finally put the molecule in a real creature — one at a time — and see if it actually does what you think it does. Manifold Bio’s molecular machinery could let a hundred molecules be tested simultaneously in a single living system, potentially upending the whole process.
The drug discovery space has advanced a lot in the last few years, first with fast and cheap gene transcription, then with CRISPR, then with AI-powered proteomics. You don’t have to know what all of those do, however, to understand that in the end, no matter how much they accelerate fundamental research, in vivo testing remains a major bottleneck.
In vivo means “in life,” as opposed to in vitro (in glass) or in silico (simulated), and mice are the usual critters that get the dubious honor of testing out a new drug’s safety and efficacy. And the general equation there is: one drug, one mouse. Because this is such a logistically challenging and time-consuming part of drug testing, it is usually left until there are only a handful of molecules the company or lab is fairly confident will work. But it also is the first — and often the last — time any of these drugs actually has to work in a real body, and the result is many washing out.
Enter Manifold Bio. The startup, armed with $40 million in series A funding, aims to make mouse tests a hundred times more efficient and effective, changing that equation and enabling earlier in vivo testing that verifies a molecule’s function before you dump a few million bucks worth of resources into it.
“The best test environment is reality,” explained the founder and CEO of Manifold Bio, Gleb Kuznetsov. “But as you get further in a drug development program, you’re investing more and more, to do more and more expensive experiments and work. We’re optimizing much earlier, so once we’re at that final gate of going to clinical tests, we’re moving forward with a drug that has already been optimized. If you can have more conviction that this is the right drug to be investing in, you can address the key risk of your investment.”
Currently, at the mouse testing phase, you generally have a target condition and a handful of candidate drug molecules. One goes in each mouse and you observe what happens — and there’s a real chance all of them will flunk at this crucial stage.
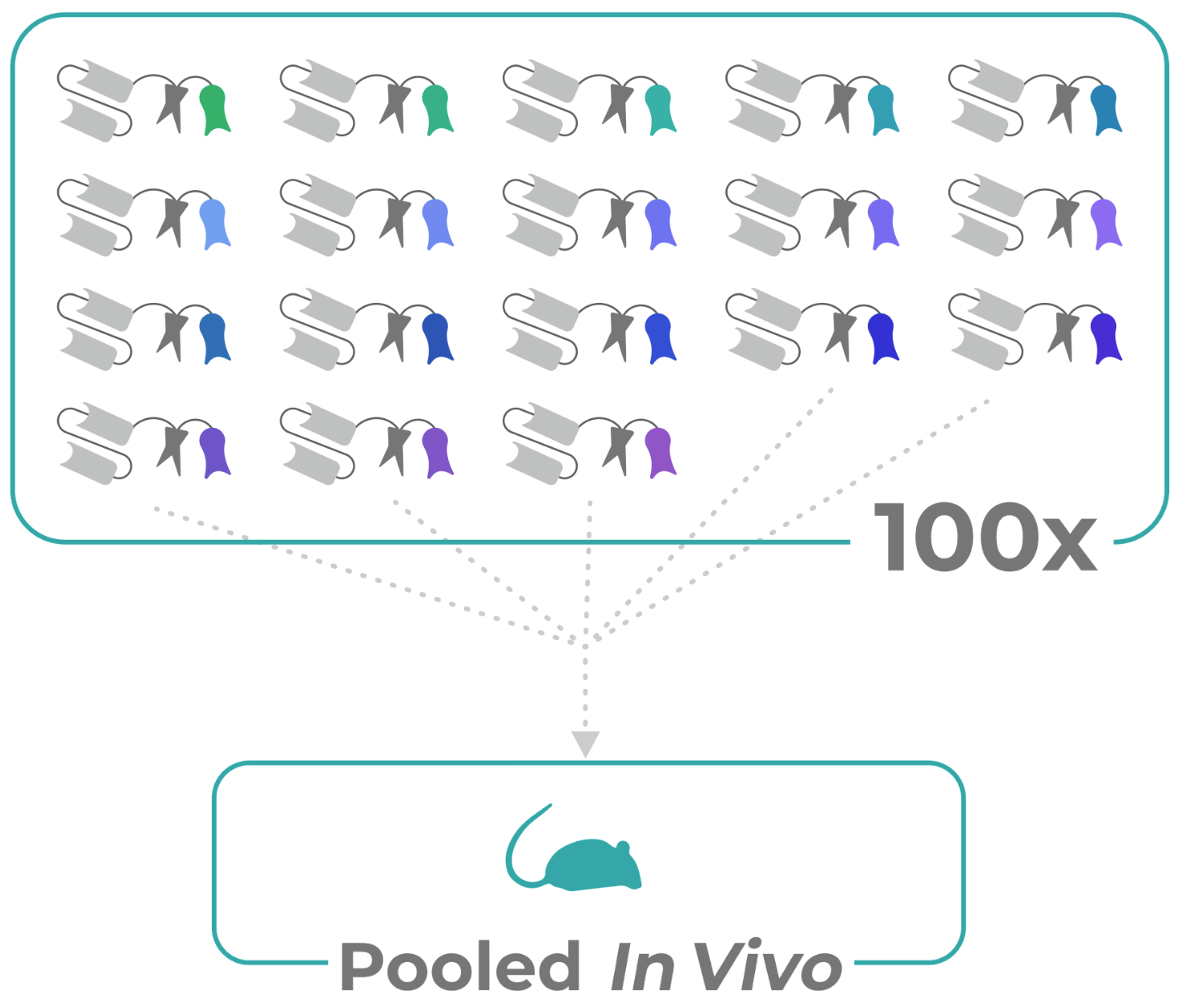
Manifold’s innovation is parallelizing in vivo testing with up to a hundred simultaneous tests in a single mouse. To make this happen it has invented a “protein barcoding” tech that you might think of as molecular RFID tags.
Illustration of multiple “barcodes” attached to proteins to be tested in vivo.
“The way it works is we attach an extra bit of protein, our protein barcode, and that makes the protein trackable and we can track it wherever it goes in a system,” Kuznetsov said. Rather than verifying lab tests, “It’s more for informing design. There’s a lot of AI and machine learning driven development, a lot of design on the computer. We focus on a specific cancer target, something on the surface of cancer cells that really flags that this is a cancer cell, and figure out the drug designs that go very specifically to those cancer cells — and don’t go anywhere else.”
The problem here is that at this stage, you might be looking at a thousand different proteins, each of which may only vary from the others by a couple amino acids, the building blocks that give proteins their shape and function.
That’s where Manifold’s barcodes come in. Each protein, however similar, gets a tag that is totally unique and identifiable after the fact when put through a proprietary DNA conversion process. Equal quantities of 100 molecules go into the mouse in, maybe 95 don’t do anything, 3 attach to the cancer decently, and 2 attach at a much higher rate. That’s 98 molecules you don’t have to take through further testing.
This screening process takes a lot of uncertainty out of the equation, since you know for sure that this protein actually does what you designed it to do, in a living mammalian system. And this is right after design and low volume synthesis, relatively cheap and early parts of the process.
From left, Manifold co-founders Gleb Kuznetsov, Shane Lofgren, and Pierce Ogden.
The tough part was designing the tags themselves. If you think about it, each little protein barcode has to meet a really high bar.
“There’s a molecular biology component but there’s also a lot of computational side of making these things detectable. They also have to not affect the behavior of the drug, and they must be stable, detectable, unique, and manufacturable,” said Kuznetsov. Designing one would be a challenge — designing 100 could be the foundation of an entirely new drug development path. He compared it to the change that happened in computing when we went from serial processing on CPUs to parallel processing in GPUs.
To be clear, though, this isn’t about supercharging testing at other companies — Manifold aims to build an entire vertically integrated drug company based on this biotech-infused approach to testing.
A Manifold Bio employee works in their wet lab.
“We’re going end-to-end internally,” Kuznetsov said. “The drugs we have in house, we created those molecules from scratch, we’ve put them in these pooled in vivo tests, and they’ll soon be at the level of clinical trials.”
Their seed round was to build the foundation and show the tech works — which it has now done. The $40M A round is to start the more expensive and standardized clinical testing process. The company is focused on cancer for now, since that’s not only a huge threat but also a good match for the types of drugs this process excels at finding.
The company is run by Kuznetsov and his co-founders, but genetics pioneer George Church helped come up with and build out the company to start. He’s currently an advisor.
The new funding round was led by Triatomic Capital, with participation from new investors Section 32, FPV Ventures, Horizons Ventures, and Tencent, and existing investors Playground Global, Fifty Years, and FAST by GETTYLAB.