For many of us, clean, drinkable water comes right out of the tap. But for billions it’s not that simple, and all over the world researchers are looking into ways to fix that. Today brings work from Berkeley, where a team is working on a water-harvesting apparatus that requires no power and can produce water even in the dry air of the desert. Hey, if a cactus can do it, why can’t we?
While there are numerous methods for collecting water from the air, many require power or parts that need to be replaced; what professor Omar Yaghi has developed needs neither.
The secret isn’t some clever solar concentrator or low-friction fan — it’s all about the materials. Yaghi is a chemist, and has created what’s called a metal-organic framework, or MOF, that’s eager both to absorb and release water.
It’s essentially a powder made of tiny crystals in which water molecules get caught as the temperature decreases. Then, when the temperature increases again, the water is released into the air again.
 Yaghi demonstrated the process on a small scale last year, but now he and his team have published the results of a larger field test producing real-world amounts of water.
Yaghi demonstrated the process on a small scale last year, but now he and his team have published the results of a larger field test producing real-world amounts of water.
They put together a box about two feet per side with a layer of MOF on top that sits exposed to the air. Every night the temperature drops and the humidity rises, and water is trapped inside the MOF; in the morning, the sun’s heat drives the water from the powder, and it condenses on the box’s sides, kept cool by a sort of hat. The result of a night’s work: 3 ounces of water per pound of MOF used.
That’s not much more than a few sips, but improvements are already on the way. Currently the MOF uses zicronium, but an aluminum-based MOF, already being tested in the lab, will cost 99 percent less and produce twice as much water.
With the new powder and a handful of boxes, a person’s drinking needs are met without using any power or consumable material. Add a mechanism that harvests and stores the water and you’ve got yourself an off-grid potable water solution.
“There is nothing like this,” Yaghi explained in a Berkeley news release. “It operates at ambient temperature with ambient sunlight, and with no additional energy input you can collect water in the desert. The aluminum MOF is making this practical for water production, because it is cheap.”
He says there are already commercial products in development. More tests, with mechanical improvements and including the new MOF, are planned for the hottest months of the summer.
 What’s special about this technique is how comprehensive it is. It uses a video of a target person, in this case President Obama, to get a handle on what constitutes the face, eyebrows, corners of the mouth, background, and so on, and how they move normally.
What’s special about this technique is how comprehensive it is. It uses a video of a target person, in this case President Obama, to get a handle on what constitutes the face, eyebrows, corners of the mouth, background, and so on, and how they move normally. It also knows how to interact with certain objects, and what they do; for instance, it can use its built-in magnets to pull open a drawer, and it knows that a ramp can be used to roll up to an object of a given height or lower.
It also knows how to interact with certain objects, and what they do; for instance, it can use its built-in magnets to pull open a drawer, and it knows that a ramp can be used to roll up to an object of a given height or lower.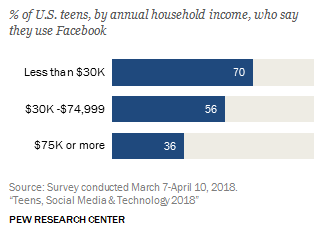 Facebook, at 51 percent, is a far cry from the 71 percent who used it back in 2015, when it was top of the heap by far. Interestingly, the 51 percent average is not representative of any of the income groups polled; 36 percent of higher income households used it, while 70 percent of teens from lower income households did.
Facebook, at 51 percent, is a far cry from the 71 percent who used it back in 2015, when it was top of the heap by far. Interestingly, the 51 percent average is not representative of any of the income groups polled; 36 percent of higher income households used it, while 70 percent of teens from lower income households did.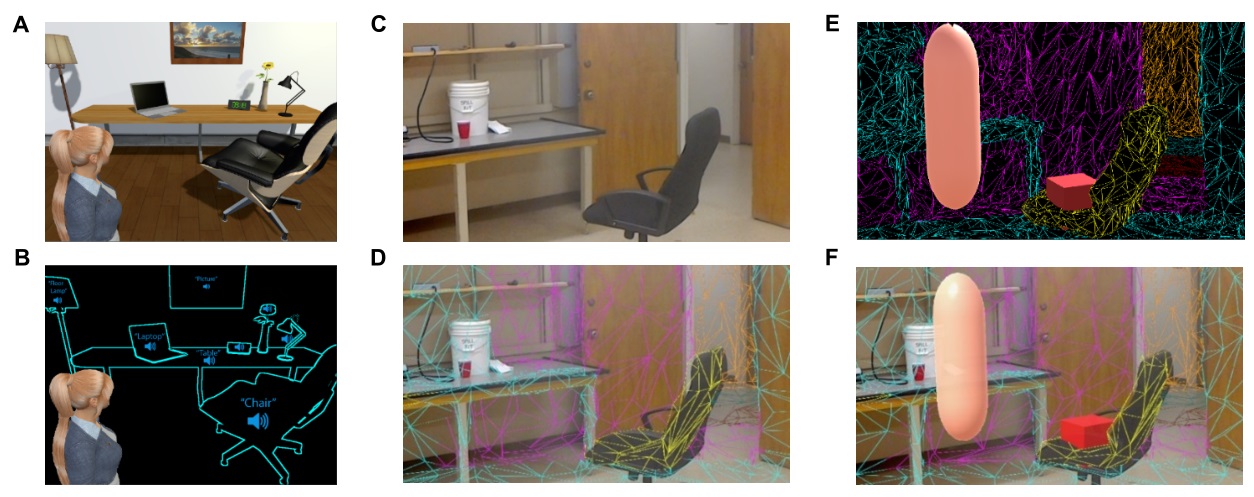 They designed the system around sound, naturally. Every major object and feature can tell the user where it is, either via voice or sound. Walls, for instance, hiss (presumably a white noise, not a snake hiss) as the user approaches them. And the user can scan the scene, with objects announcing themselves from left to right from the direction in which they are located. A single object can be selected and will repeat its callout to help the user find it.
They designed the system around sound, naturally. Every major object and feature can tell the user where it is, either via voice or sound. Walls, for instance, hiss (presumably a white noise, not a snake hiss) as the user approaches them. And the user can scan the scene, with objects announcing themselves from left to right from the direction in which they are located. A single object can be selected and will repeat its callout to help the user find it.