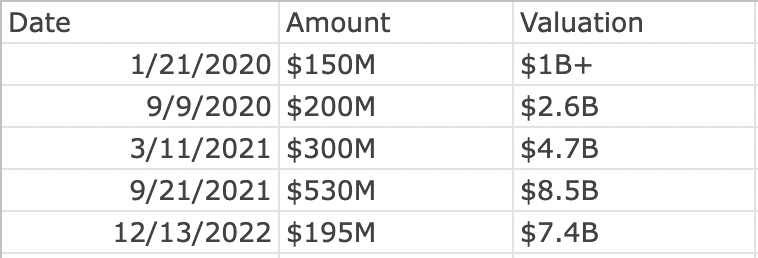
Since its launch as an open-source project by Yandex in 2016, ClickHouse has become one of the leading databases for online analytical processing (OLAP), allowing businesses to quickly generate ad-hoc reports over very large datasets. In 2021, Yandex spun off ClickHouse into its own company and joined an initial $50 million Series A funding round led by Index Ventures and Benchmark Capital. Two months later, Coatue and Altimeter led the company’s Series B round, with participation from Index Ventures, Benchmark, Lightspeed and Redpoint. Now, ClickHouse is extending this round with fresh capital from Thrive Capital.
The company, which is headquartered in San Francisco and has a European engineering base in Amsterdam, did not disclose the exact size of Thrive’s investment, but ClickHouse CEO Aaron Katz stated that it was an “eight-figure round”.
“ClickHouse offers the most efficient database for fast and large-scale analytics,” said Avery KIemmer, an investor at Thrive Capital. “We have long admired this team, and are excited to partner with them as they launch ClickHouse Cloud to an even wider audience.”
In addition to announcing the new funding, the company also today launched ClickHouse Cloud, a fully managed, SOC 2 Type 2-compliant cloud-hosted version of its database that is now available in the AWS Marketplace. Support for Google Cloud Platform and Microsoft’s Azure cloud is in the works. The company first launched this service into beta a few months ago and is now ready to launch it into GA.
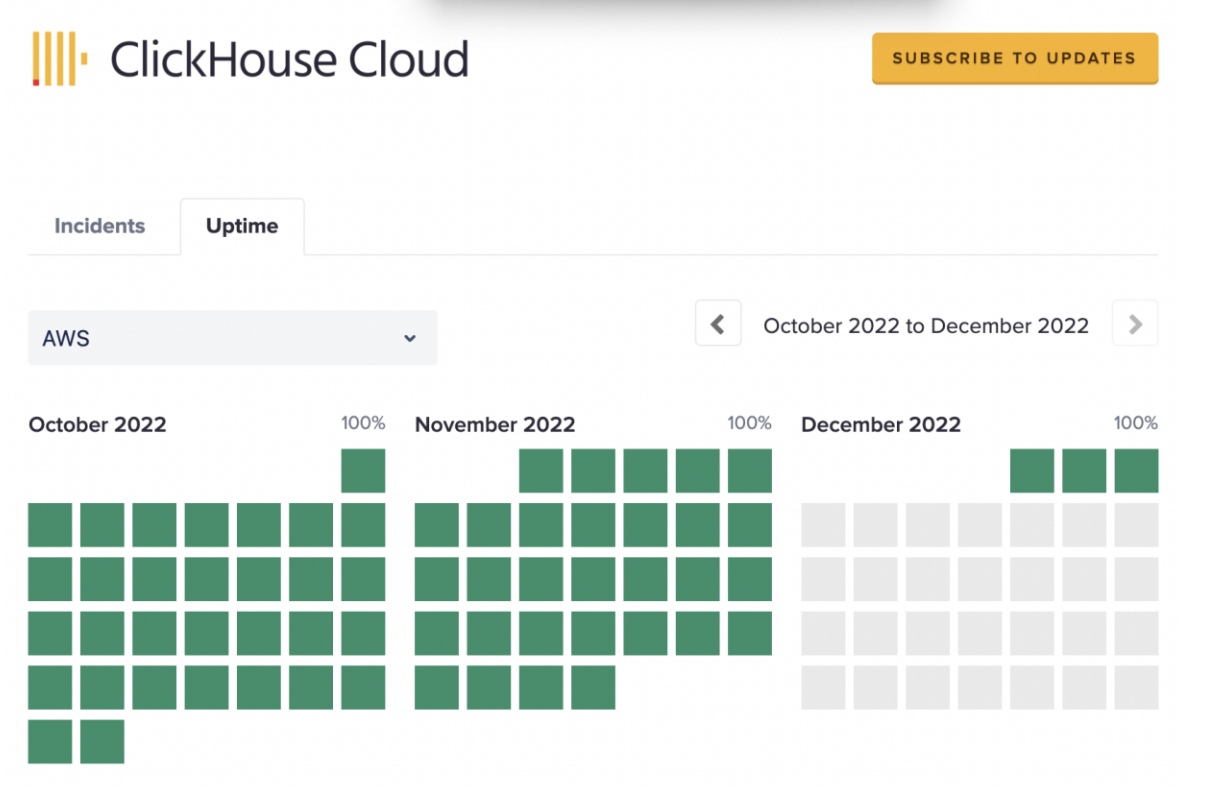
Image Credits: ClickHouse
Maybe because of its origins within Yandex, ClickHouse has flown a bit under the press’ radar, but it’s currently in use by the likes of Cloudflare, Uber, eBay, Comcast and Cisco. It’s also very hard to have a conversation about databases and analytics these days without the company being referenced in some form or another.
To run ClickHouse, Yandex brought on former Elastic CRO and Salesforce exec Aaron Katz as the company’s co-founder and CEO. Unlike other open-source companies, the ClickHouse team decided to skip past launching enterprise versions or go for an open-core model with proprietary features and skip right to a cloud-hosed version. Katz explained that this decision was based on the previous experience of the founding team.
“Trying to develop both on-premise software and sell support and stand up an enterprise-grade cloud service can be challenging to do simultaneously,” he said. “We believe the future is in managed services: serverless cloud offerings that are cloud agnostic and multi-cloud — that are secure and reliable and scalable, resource efficient and highly performant. So we developed ClickHouse Cloud and we launched it earlier this year as a beta state and got overwhelmingly positive response from the market.”
In October, ClickHouse acquired Arctype, a cross-platform GUI for managing and querying databases (think a modern phpMyAdmin). Arctype itself only launched half a year before that, so ClickHouse moved quickly here and as Katz noted, with a full war chest, we’ll likely see the company make more of these smaller acquisitions in the future. The team has now re-written Arctype as a native offering inside of ClickHouse Cloud.
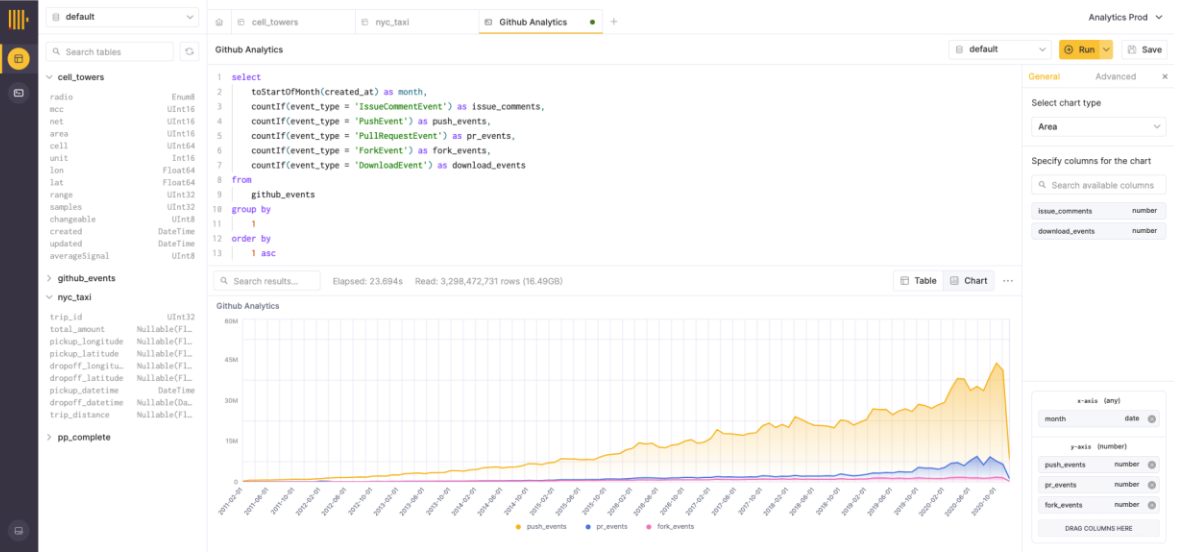
Image Credits: ClickHouse
As ClickHouse VP of Product Tanaya Bragin noted, the company also tuned the software to increase performance and added a lower pricing tier for developers who want to get started with the service (after a free 30-day trial). And because there is still a talent crunch for database experts, ClickHouse is also launching ClickHouse Academy with a catalog of free courses and recordings of its own onboarding workshops.
Bragin also stressed that current users of the ClickHouse open-source version will be able to easily migrate to ClickHouse Cloud. From the application’s perspective, the two versions are equivalent. The advantage of the hosted version, of course, is that users won’t have to manage a complex database system themselves. The system will automatically handle sharding, replication and upgrading. Auto-scaling, too, is built into ClickHouse Cloud. “The separation of storage and compute is an important accomplishment that the customers benefit from, which makes it more resource efficient and cost effective than running it on your own,” Katz added.
The ClickHouse team plans to use the new funding on expanding its product and engineering teams. Given its focus on product-led growth (PLG), the company doesn’t plan to focus too much on expanding its marketing efforts for the time being.
“We’re really pursuing this PLG distribution model, where you can go to ClickHouse Cloud today, you can create your own free trial and we give you free credits,” Katz said. “It’s totally frictionless. You never have to talk to anybody and sales. You can evaluate the service on your own. If you like what your experiencing, you can add your credit card and pay as you go monthly with totally transparent, consumption-based billing. If we get that right — and the feedback from these early 100+ customers has been very encouraging. Then we won’t need to have a really expensive sales and marketing engine, because with the PLG motion, the product will distribute itself.”
ClickHouse launches ClickHouse Cloud, extends its Series B by Frederic Lardinois originally published on TechCrunch