
Databricks, the big data analytics service founded by the original developers of Apache Spark, today announced that it is bringing its Delta Lake open-source project for building data lakes to the Linux Foundation and under an open governance model. The company announced the launch of Delta Lake earlier this year and even though it’s still a relatively new project, it has already been adopted by many organizations and has found backing from companies like Intel, Alibaba and Booz Allen Hamilton.
“In 2013, we had a small project where we added SQL to Spark at Databricks […] and donated it to the Apache Foundation,” Databricks CEO and co-founder Ali Ghodsi told me. “Over the years, slowly people have changed how they actually leverage Spark and only in the last year or so it really started to dawn upon us that there’s a new pattern that’s emerging and Spark is being used in a completely different way than maybe we had planned initially.”
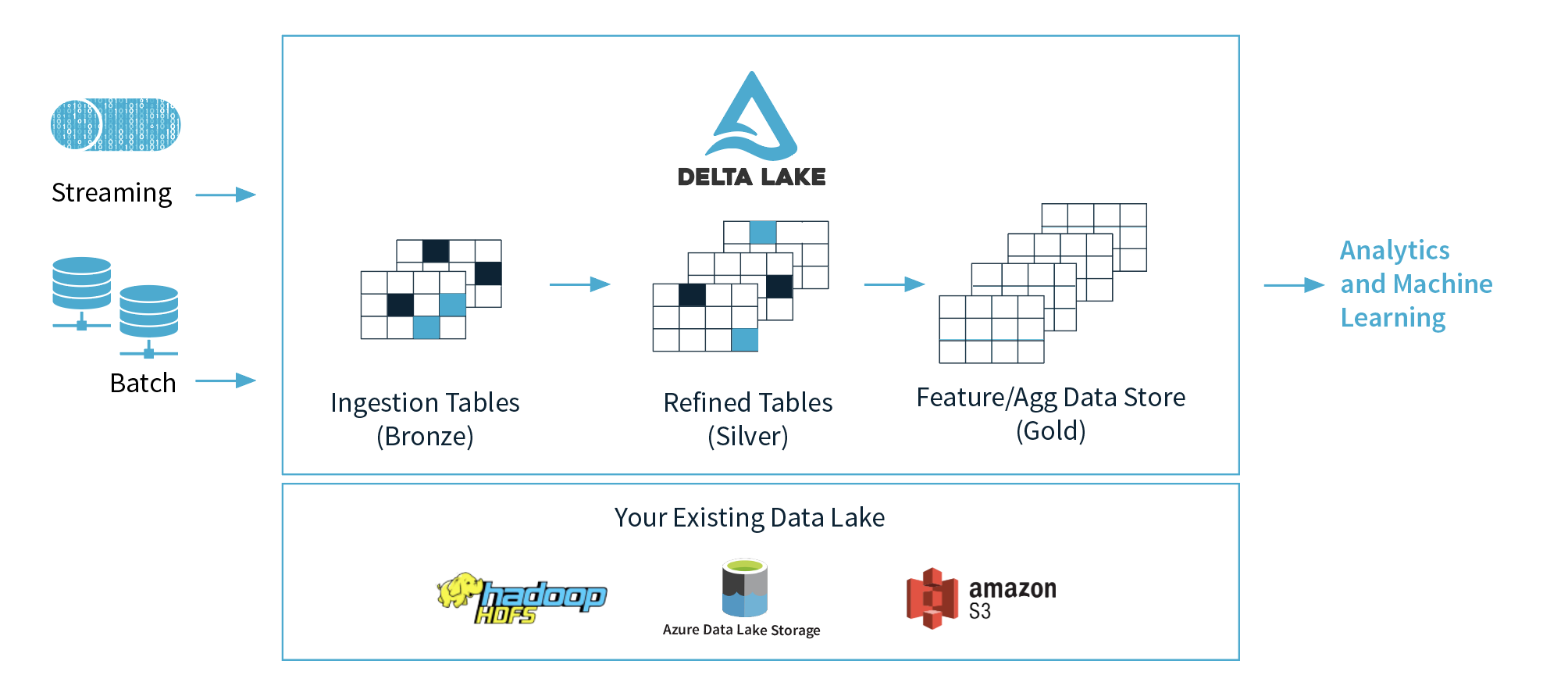
This pattern, he said, is that companies are taking all of their data and putting it into data lakes and then do a couple of things with this data, machine learning and data science being the obvious ones. But they are also doing things that are more traditionally associated with data warehouses, like business intelligence and reporting. The term Ghodsi uses for this kind of usage is ‘Lake House.’ More and more, Databricks is seeing that Spark is being used for this purpose and not just to replace Hadoop and doing ETL (extract, transform, load). “This kind of Lake House patterns we’ve seen emerge more and more and we wanted to double down on it.”
 Spark 3.0, which is launching today, enables more of these use cases and speeds them up significantly, in addition to the launch of a new feature that enables you to add a pluggable data catalog to Spark.
Spark 3.0, which is launching today, enables more of these use cases and speeds them up significantly, in addition to the launch of a new feature that enables you to add a pluggable data catalog to Spark.
Data Lake, Ghodsi said, is essentially the data layer of the Lake House pattern. It brings support for ACID transactions to data lakes, scalable metadata handling, and data versioning, for example. All the data is stored in the Apache Parquet format and users can enforce schemas (and change them with relative ease if necessary).
It’s interesting to see Databricks choose the Linux Foundation for this project, given that its roots are in the Apache Foundation. “We’re super excited to partner with them,” Ghodsi said about why the company chose the Linux Foundation. “They run the biggest projects on the planet, including the Linux project but also a lot of cloud projects. The cloud-native stuff is all in the Linux Foundation.”
“Bringing Delta Lake under the neutral home of the Linux Foundation will help the open source community dependent on the project develop the technology addressing how big data is stored and processed, both on-prem and in the cloud,” said Michael Dolan, VP of Strategic Programs at the Linux Foundation. “The Linux Foundation helps open source communities leverage an open governance model to enable broad industry contribution and consensus building, which will improve the state of the art for data storage and reliability.”


