TVSmiles, a Berlin-based mobile native advertising app whose users earn digital currency in exchange for engaging with branded content such as quizzes, apps and videos, has suffered a data breach.
Security researcher UpGuard disclosed in a report today that it found an unsecured Amazon S3 bucket online last month — containing personal and device data tied to millions of the app’s users. According to TVSmiles’ marketing material the quiz app has up to three million users.
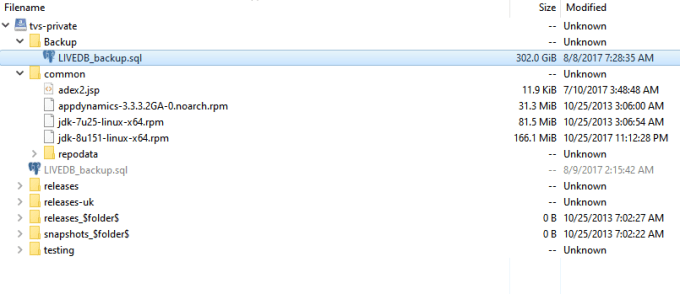
The storage bucket UpGuard found exposed to the Internet contained a 306 GB PostgreSQL database backup with “unencrypted personally identifiable information matched to individual users, profiling insights about users’ interests based on quiz responses, associations to smart devices, and accounts and login details for TVSmiles’ business relationships”, according to its report.
UpGuard writes that 261 database tables were present in the exposed repository — including a “core_users” table consisting of more than 6.6 million rows. Of the entries that had an email address tied to them UpGuard says it found 901,000 unique emails.
The exposed backup file appears to date back to August 2017.
Screengrab: UpGuard
After UpGuard reported the breach to TVSmiles, in an email sent May 13, the Berlin -based company responded on May 15, writing in an email that the repository “has been immediately secured” (UpGuard says it independently confirmed this).
TVSmiles co-founder, Gaylord Zach, added in this email to UpGuard that it would “further investigate the contents of the exposed data to take further actions”.
Reached for comment on the incident today, Zach confirmed UpGuard’s report and also confirmed that the exposed repository had been accidentally left unsecured for years.
He said internal analysis of available logs has found no unauthorized access besides UpGuard’s access of the data, adding that TVSmiles has yet to notify users of the incident — but is planning a communication to users within its mobile app and a blog post on its website.
“Our analysis has revealed that the data consists of a database backup that was created in 2017 and mistakenly stored in a cloud storage repository provided within the cloud hosting environment,” Zach told us. “Allegedly this backup was created as a safety measure ahead of performed maintenance work. Further investigation revealed three independent but severe policy breaches: 1.) The backup was stored in plain format where all backups should have been encrypted; 2.) The affected repository was provisioned as a code repository and never intended to store data; 3.) The affected repository was intended for private use within the organization and never intended to be publicly available.
“The very unfortunate combination of these three factors resulted in the long period that this data remained stored without discovery.”
TVSmiles reported the breach to the German Data protection authorities — filing its report on May 17, per Zach.
Europe’s General Data Protection Regulation (GDPR) requires data controllers to report all breaches of personal data that pose a risk to people’s rights and freedoms to a supervisory authority within at least 72 hours of discovery.
“We are very thankful to UpGuard unveiling this exposure before it has led to material data breaches and harm to our users. We are very much embarrassed by this unnecessary exposure of user data. It is a strong reminder to every developer to do regular security checks and house keeping in order to avoid these incidents,” he added.
Screengrab: UpGuard
Clicks for data
TVSmiles’ business participates in a data-fuelled digital ad ecosystem that operates by linking user IDs to devices, digital activity and tracked interests, building individual profiles for the purpose of targeting screen users with advertising.
Hence the interactive content that the TVSmiles quiz app encourages users to engage with — rewarding activity with a proprietary digital currency (called ‘Smiles’) that can be exchanged for discount vouchers on products in its shop or directly for cash — functions both as direct marketing material to drive deeper engage around branded content; and a data harvesting tool in its own right, enabling the business to gather deeper insights on users’ interests which can in turn be monetized via user profiling and ad targeting.
Such insights enable TVSmiles to plug into a wider digital advertising ecosystem in which mobile users are profiled and tracked at scale across multiple apps, services and devices in order that targeted ads can follow eyeballs as they go — all powered by the background profiling of people’s digital activity and inferred interests.
According to Crunchbase the quiz app has raised a total of $12.6M in funding since being founded around seven years ago when it was pitching itself as a second screen app for TV viewers. It went on to launch its own ad platform, called Kwizzard, which packages ads into “a native, gamified ad format” — with the aim of luring app users to engage with quiz-based ad campaigns.
Given the nature of TVSmiles’ business — and a wider problematic lack of transparency around how the adtech industry functions — this data breach is a fascinating and unnerving glimpse of the breadth and depth of data harvesting that routinely goes on in the background of ad-supported digital services.
Even an app with a relatively small user base (single digit millions) can be sitting atop a massive repository of tracking data.
The online ad industry also continues to face major questions over the legal basis it claims for processing large volumes of personal data under the European Union’s data protection regime.
A master database plus access tokens
In terms of the types of data exposed in this breach, UpGuard said the 306 GB PostgreSQL database backup contained “centralized information” about users of the app, alongside what it describes as “large amounts of internal system and partnership information necessary for any business participating in the modern online advertising ecosystem”.
TVSmiles’ LinkedIn page reports the app having in excess of 2M users in Germany and the U.K. — per Google’s Play store the TVSmiles app has had in excess of 1M downloads to date, and while Apple’s iOS does not break out a ballpark figure for app downloads a video on the Play Store app page makes reference to 3M users — so it’s possible the 6.6M figure relates to total downloads over the app’s lifetime since launch back in September 2013.
Zach told us that the discrepancy between the user figures is a result of TVSmiles being a much smaller business now than it was in mid 2017 — when it was spending a lot on marketing and had more active users, including as a result of operating in the UK market (which it left in 2018).
“In general we are now a much smaller organisation compared to 2017,” he added.
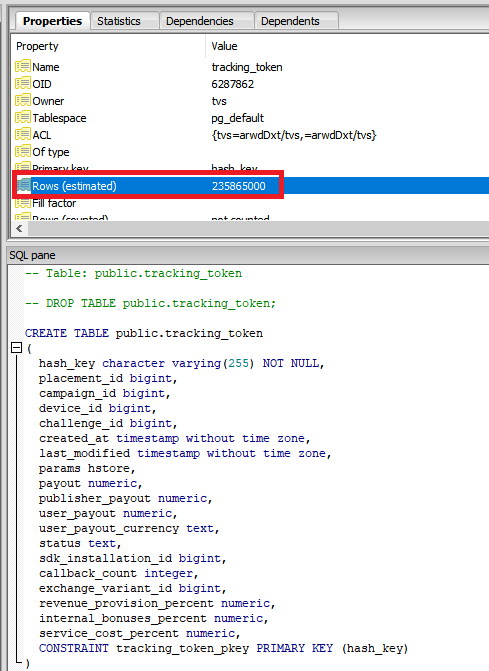
Other tables in the repository were found by UpGuard to contain considerably more entries — such as a “tracking_token” table, with more than 235 million entry rows.
“A table in this database called “user_core” contained six million rows, with many users having their “country” field marked for other territories throughout Europe, making this data consistent with being a master database for TVSmiles at the time,” it writes in the report. “The user_core table contained fields for email address, fb_user, fb_access_token, first and last name, gender, date of birth, address, phone number, password, and others.”
UpGuard told us that the user_core table had password hashes filled in for 626,000 of the rows. It said these passwords appear to have been hashed using a type of hashing algorithm that’s known to be vulnerable to brute forcing — the sha256 algorithm — and therefore offers little protection against malicious attackers.
It added that it was able to locate three out of three random hashed passwords it checked in publicly available indexes which are easily searchable online — meaning these password hashes had already been reversed (which in turn suggests they may have been used elsewhere before; or else are commonly guessable).
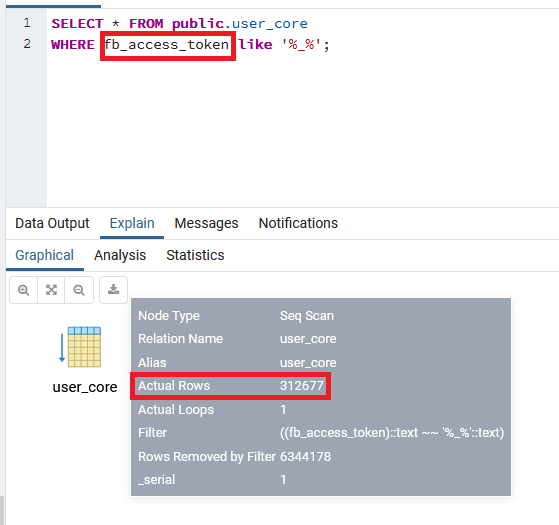
It also found Facebook user IDs (“fb_user”) and access tokens (“fb_access_token”) stored in the repository for some of the listed TVSmiles users — presumably for those who used a Facebook account to login to the app.
“Not all data points were present for all users – for example, the Facebook specific fields would likely only be present for users who had connected with their Facebook identity, and users who had authenticated via Facebook would not inherently need to create a password for the app due to the functionality of that authentication method,” UpGuard suggests.
The exposed repository contained more than 312,000 access tokens tied to Facebook IDs, according to its analysis.
Screengrab: UpGuard
It also found a large collection of personal data stored in a table related to end user devices — which it said were linked to tracking tokens, ad IDs and user rewards.
“A table called “device_core” contains 7.5 million rows tied to physical devices,” UpGuard writes. “These devices have unique device ids, access tokens, and mappings to the user ids of their owners. Those device ids, in turn, are then relevant to a “tracking_token” table consisting of 235 million entry rows.
“The rows in the tracking_token table include fields such as campaign_id, placement_id, user_payout, and challenge_id, building up a picture of the TVSmiles activity – like which ads and activities users responded to – on each device – which can then be linked back to the user.”
Other personal data found in the repository includes precise location data — “users’ latitude and longitude” — with a related admin view configured for a database named “full device info”, which UpGuard says highlights “the “tracker_name,” a token value, and the nearest weather station”.
It also found a collection of “insights” related to TVSmiles users — listed in the form of “intents, interests, and other psychographic qualities”.
“These subjects ranged from consumer goods (e.g. books, video games, furniture, and clothing) to the user’s education and more esoteric interests,” the report notes.

Redacted screengrab: UpGuard
As well as storing (unencrypted) personal data attached to millions of users of the TVSmiles app, and hashed passwords for more than half a million of these entries, the exposed repository was found to contain information related to a number of the company’s own business clients — also tied to access tokens.
“It is reasonable to interpret these names as business clients, who have paid to publish ads on TVSmiles or have access to insights gleaned from end-user app interaction,” UpGuard writes of the “business_clients” table.
“These business users’ hashed passwords, phone numbers, email addresses, names, and other data points were also present. Conversely, TVSmiles’ own credentials for interacting with vendors necessary to provide the TVSmiles platform, like ad exchanges, fraud detection platforms, and email communication scheduling, were also present.”
UpGuard suggests that a hacker who stumbled across the unsecured bucket may have been able to use the tokens to gain access to a number of additional services where they could potentially obtain further user data — such as by exporting contact data; accessing or sending mail via a third party service; or reading historic service information and performance metrics.
“If this database had been located by malicious entities, prior to UpGuard discovering it and sending appropriate notification, the possibility exists that such credentials could have allowed an attacker to impersonate TVSmiles and collect additional information about arbitrary targets from those other platforms and service providers,” it adds.
Zach confirmed the data contained “legacy access tokens” — but said they stem from a deprecated login methodology that had since been replaced with a OAuth based sign on service.
“The data originates from August 2017. Any contained access tokens would therefore have expired by now,” he told us, saying TVSmiles has not yet notified any business partners on account of seeing “no major risk based on the nature and age of the exposed tokens”.
“We would however not hesitate to contact and take action if we have underestimated or overseen risks,” he added.
Questions of consent
After reviewing UpGuard’s report, Wolfie Christl, an EU-based privacy researcher who focuses on adtech and data-driven surveillance, called for EU data protection agencies to launch an immediate investigation.
“This is a massive data breach. But it is about more than that. It provides a glimpse into an opaque industry consisting of thousands of companies that secretly harvest extensive personal information on millions of people for business purposes,” he told TechCrunch.
“According to the leaked database, the company has digital profiles on 6M people and 7.5M devices. It seems that they linked names, email addresses and phone numbers to device identifiers, social media accounts, and to all kinds of behavioral data.
“Data protection authorities in Germany — and perhaps in other European countries — must immediately start an investigation. In addition to the data breach, they must examine whether the company, and its affiliates and partners, processed this extensive amount of personal data in a lawful way. Did they have a legal basis to process it?”

Screengrab: UpGuard
“The wider issue is that, two years after the GDPR came into full force, it has still not been enforced in major areas,” Christl added. “We still see large-scale misuse of personal information all over the digital world, from platforms to digital marketing to mobile apps. EU authorities should have acted years ago, they must do so now.”
In its privacy policy, TVSmiles states that it only uses app users’ personal data “to the extent that this is legally permissible or you have given your consent… for the purposes of advertising, market research or the needs-based design of our offer” [text translated using Google Translate].
“We are obtaining user consent to the use of data and have created a dedicated section within our app to obtain consent like location data, advertising identifier, sharing of personal data with advertising partners,” Zach told us on this, adding that consent information is provided to “various advertising and tracking partners” — assuming users agree to be tracked via responses to its consent flows (shown below).
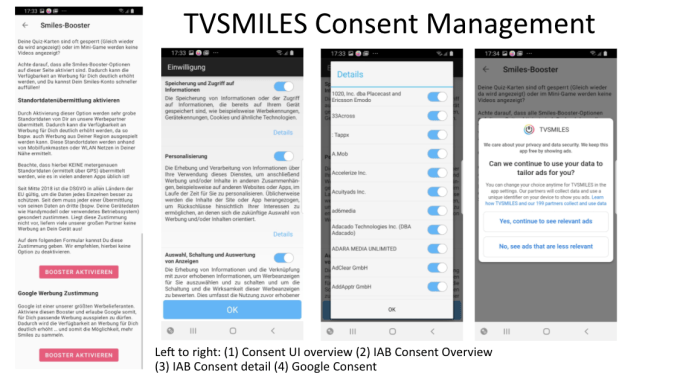
Screenshots: TVSmiles
References to a number of third party adtech companies can be found in TVSmiles’ repository, per UpGuard, suggesting it was making use of their services for data structuring, enrichment and monetization purposes — including Adex, a data management platform and marketplace whose website touts the “easy selling and purchase of data”; Adjust, a mobile measurement and fraud-prevention firm geared towards mobile marketing; mobile app monetization company, Fyber; and product user behavior analytics platform, Mixpanel.
Another interesting component in this story is how TVSmiles’ business straddles the TV and online advertising realms. Its business began, more than half a decade ago, with a firm focus on the notion of being a ‘second screen’ app for TV viewers — including by using audio technology to automatically identify TV ads in order to serve related in-app content. This means it’s forged links with traditional media giants.
Back in 2014, for instance, it inked a marketing partnership for its app in Austria with European media giant ProSiebenSat.1’s marketing subsidiary, SevenOne Media. At the time ProSiebenSat.1 PULS 4’s MD, Michael Stix, billed the move as a “strategic step” to integrate brand communication on the second screen, lauding the tie-up as a way to offer advertising customers “additional novel touchpoints” for their target group.
But the rise of smart TVs and digital sign-ins has paved the way for deeper linking of Internet activity and TV viewing. Especially as traditional mass media giants have been looking for ways to diversify their media businesses, with more competition for viewers’ eyeballs than ever before.
Behind all these screens a complex mass of adtech pipes is exchanging data linked to individual users — trading IDs and insights to join dots and serve targeted ads. So connected “touchpoints” are now very much integral, not secondary, these days.
UpGuard found labels (see below screengrab) in the exposed TVSmiles repository that refer to “seven_pass”: Aka a single sign-on solution for all ProSieben.Sat1’s digital services, called 7Pass.
An FAQ on TVSmiles’ website confirms TVSmiles users are able to use the 7Pass service to log in to the app.
Screengrab: UpGuard
In its privacy policy, TVSmiles states that “pseudonymized” data of users of the 7Pass login is sent to ProSiebenSat.1 Digital & its affiliates and to other affiliated companies of ProSiebenSat.1 Media SE — including quiz response data.
“In addition, survey data collected and provided by you via survey cards in the app are also transmitted pseudonymised to ProSiebenSat.1 Digital & Adjacent GmbH and other affiliated companies of ProSiebenSat.1 Media SE in order to enable you to use special quiz cards in the app, bring in more smilies and be able to offer special promotions in cooperation with ProSiebenSat.1,” it adds.
Of course, much like weak password hashes, “pseudonymised” personal data can be trivially easy to re-identify — such as by unifying tracking IDs.
Asked about the 7Pass service, Zach said TVSmiles had replaced its legacy user management with ProSiebenSat.1’s digital sign-on service — claiming the main objective was “to leverage a trustworthy well maintained sign-on service by a larger partner and remove the need of self managed credentials and access tokens”.
“Given the sensitivity of user data and access credentials it seems like a wise choice in light of this case,” he added.
In a more recent business development, TVSmiles sold its development division and adtech to a company called PubNative in December 2019. PubNative is a mobile SSP and programmatic ad exchange owned by a German holding company called MGI Media that’s made a large number of media and adtech acquisitions in recent years (as well as being majority owner of free-to-play gamesmaker, Gamigo).
At the time of this “acqui-hire” TVSmiles and PubNative suggested an ongoing business partnership. “As we recently branched into Connected TV, PubNative’s advanced tech stack supports our continued growth and allows us to expand our business internationally. Advancements on demand-side business development will be introduced gradually across the entire product line,” said Zach in a press statement at the end of last year.
Asked about the nature of the business relationship between TVSmiles and PubNative, Zach confirmed it sold “certain people and technology” to PubNative but retained its mobile apps and user base, adding: “No user data has been shared with PubNative and they have no involvement in this case.”
However he confirmed TVSmiles uses advertising technology provided by PubNative.
“This technology (SDK) is built into the TVSmiles app. Data sharing is limited to those authorized by user consent for advertising use,” he added.
A static analysis by Exodus suggests the TVSmiles app contains more than 40 trackers — including PubNative’s. This plus the fact the TVSmiles repository was found by UpGuard to be storing precise user location data is interesting in light of a separate report, published in January, by Norway’s Consumer Council (NCC) — which delved into how the adtech industry non-transparently exploits app users’ data.
The NCC report identified PubNative as one of the entities receiving GPS data from a number of apps it tested (NB: it did not test the TVSmiles app). The Council found a majority of apps that it did test transmitted data to entities it characterized as “unexpected third parties” — meaning users were not being clearly informed about who was getting their information and what was being done with it, in its view.
Other SDKs contained in the TVSmiles app, per Exodus and a list of software suppliers in TVSmiles’ privacy policy, include Facebook Ads, Analytics and Places; Google Ads, Analytics, DoubleClick & more; and Twitter MoPub. Also present: A longer list of smaller adtech and mobile marketing/monetization players, from AdBuddiz to Vungle.
“Looking through the Exodus report most of these trackers stem from advertising technology that is being used within TVSmiles app,” Zach also told us.


 member
member